카프카핵심가이드 1장 - 카프카 프로듀서
카프카 핵심가이드 책을 읽은 내용 정리
발행/구독 메시지 전달
발행/구독메시지 전달(publish/subscribe messaging) 패턴의 특징은 전송자가 데이터를 보낼 때 직접 수신자 쪽으로 보내지 않는다는 것이다. 중간에서 중계해주는 브로커를 이용하여 메시지를 전달한다.
초기의 발행/구독 시스템
대부분 비슷한 형태로 시작한다. 가운데 간단한 메시지 큐나 프로세스간 통신 채널을 놓는다. 아래의 그림은 2개의 frontend server가 metric server로 application metric을 보내게 구성해놓았다.
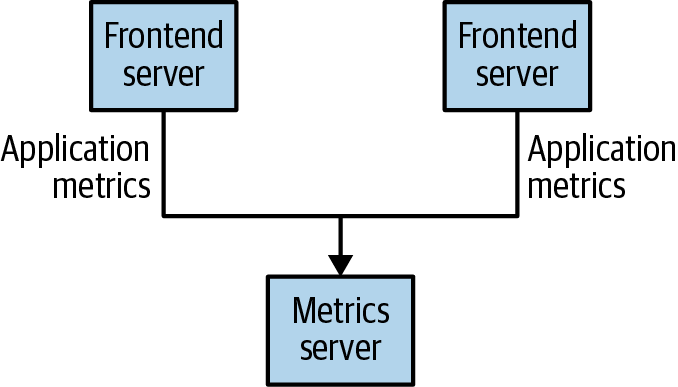
만약 metric server가 n개가 된다면 어떻게 될까? 그리고 frontend server 뿐만 아니라 다른 서버들이 metric을 발행/구독하게 된다면 아래와 같이 복잡해 질 것이다.
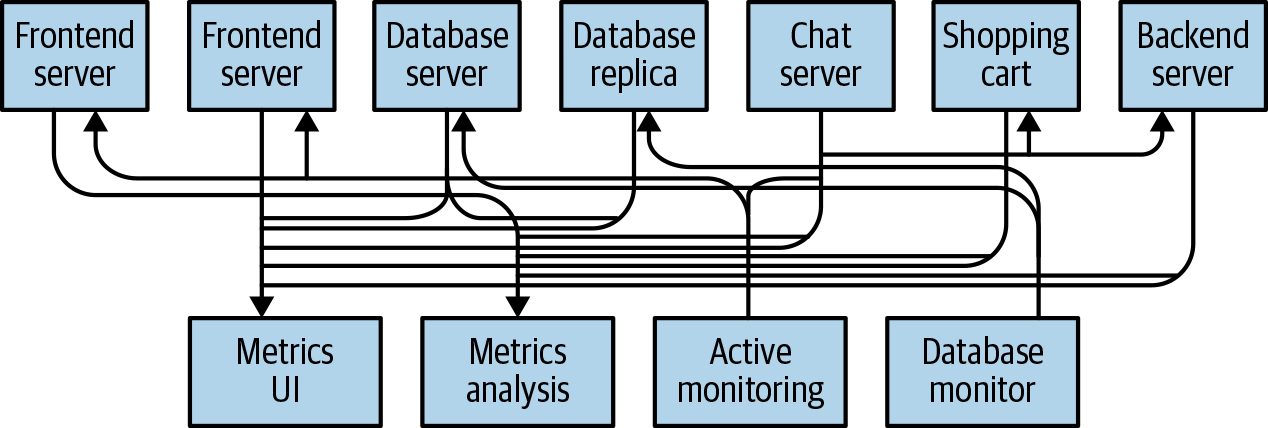
이처럼 각 application server가 직접 통신을 하게된다면 확장성이 매우 떨어지게 된다. 그래서 확장성을 높이기 위해 중간에 브로커를 두어 해결 할 수 있게 된다.
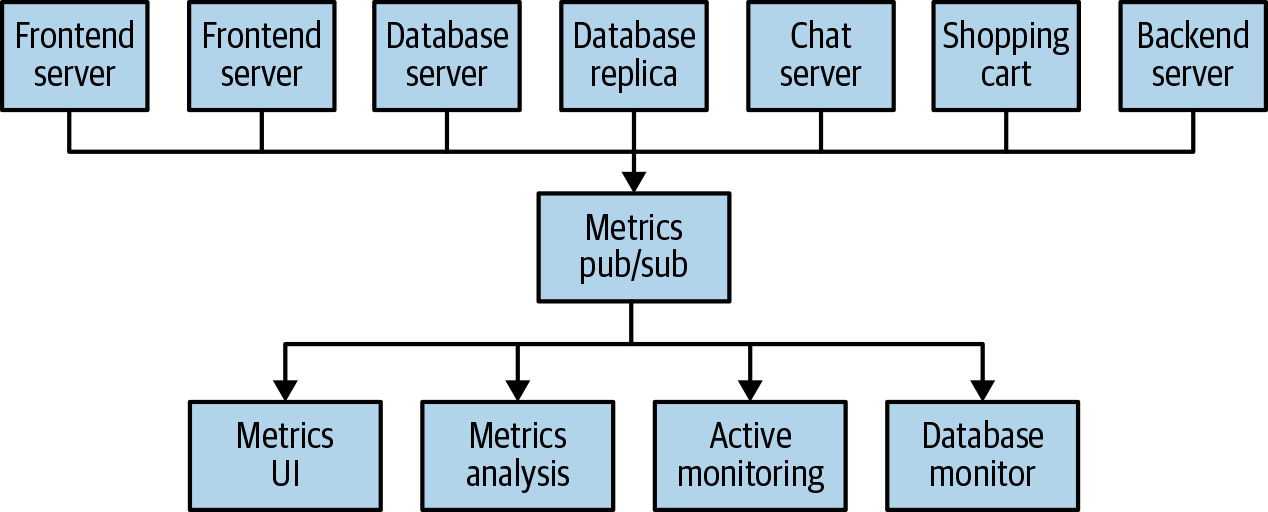
개별 메시지 큐 시스템
앞선 그림에서 조금더 확장 시켜 여러개의 broker를 둔다면 비즈니스가 확장되어도 유연하게 대처가 가능할 것이다. 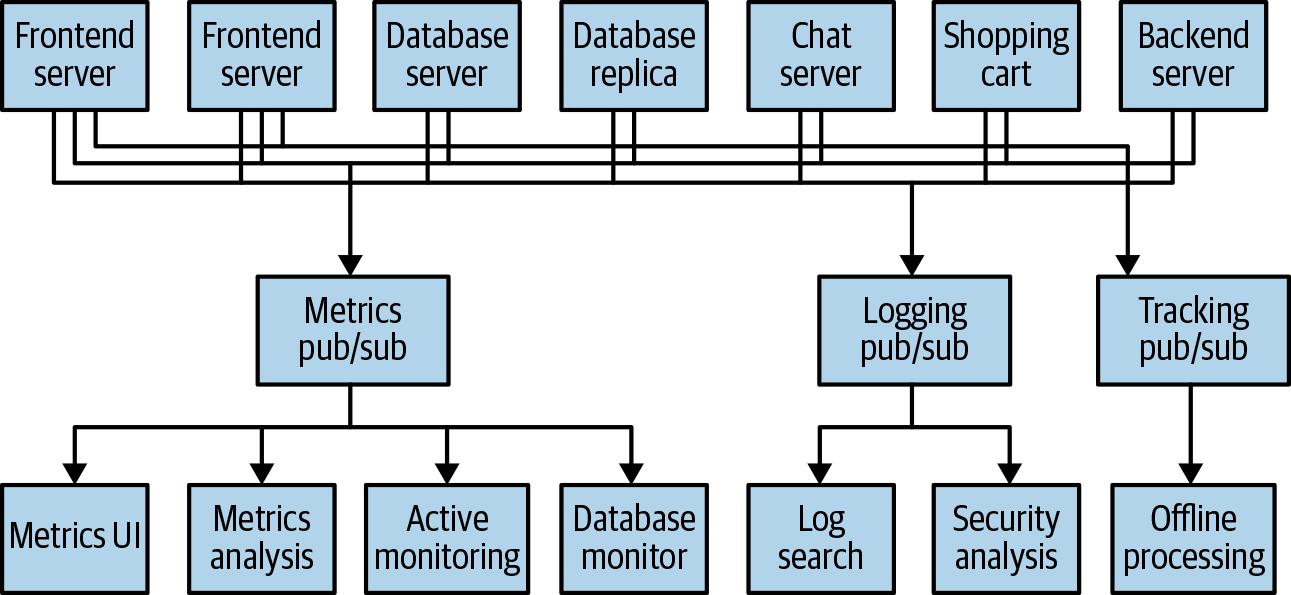
카프카 입문
카프카는 위에서 설명한 문제를 해결하기 위해 고안된 메시지 발행/구독 시스템이다. “분산 커밋 로그”, “분산 스트리밍 플랫폼”이라고도 불린다.
카프카는 데이터의 순서를 유지한채 저장하며, 모든 트랜잭션 로그를 보존함으로써 일관성 있게 복구가 가능하다. 그리고 또한 데이터를 분산시켜 저장한다.
메시지와 배치
메시지: 데이터의 기본 단위다.key: 메타데이터로써 메시지를 저장할 파티션을 결정할때 사용된다.배치: 같은 토픽의 파티션에 쓰여지는 메시지들의 집합이다. 메시지를 배치 단위로 저장한다. 메시지를 배치 단위로 모아서 쓰면 네트워크 오버헤드를 줄일 수 있다.
배치 사이즈가 커지면 시간당 처리되는 메시지 수는 늘지만 각각의 메시지가 전달되는데 시간은 늘어난다.
스키마
카프카 입장에서 메시지는 단순한 바이트 배열뿐 이지만, 내용을 이해하기 쉽게 일정한 구조(스키마)를 부여하는 것이 권장된다.
XML, JSON, avro, proto 등으로 스키마를 저으이하여 데이터의 일관된 형식을 유지하게 한다.
토픽과 파티션
카프카에 저장되는 메시지는 topic이라는 단위로 분류된다.
Topic은 다시 여러 Partition으로 나뉜다.
partition에 메시지가 쓰일 때, append-only(추가만 가능한 형태)로 쓰인다. 읽을 땐 맨 앞부터 끝까지의 순서로 읽힌다.
토픽에 여러 파티션이 있는 경우, 토픽 안의 메시지 전체에 대한 순서는 보장되지 않는다. 다만, 단일 파티션의 경우만 순서가 보장된다.
아래의 그림에서 설명하자면 각각의 partition별로는 순서가 보장되지만, parition0의 데이터와 parition1의 데이터의 메시지 순서는 보장되지않는다.
각 파티션이 서로 다른 서버에 저장될 수 있기에 카프카는 데이터 중복과 확장성을 제공하는 방법 중 하나이기도 하다.
하나의 토픽이 여러 개의 서버로 수평적으로 확장되어 하나의 서버의 용량을 넘어가는 성능을 보여줄 수 있다.
서로 다른 서버들의 동일한 파티션의 복제본을 저장하고 있기에, 한 서버에 장애가 발생하더라도 다른 서버에서 계속해서 읽고 쓸 수 있다.
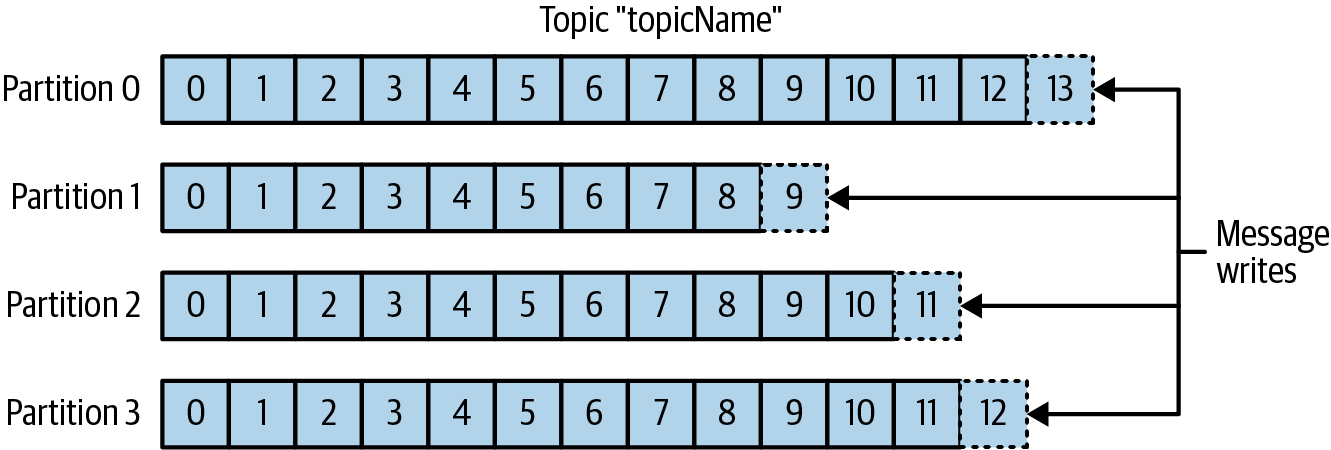
stream: kafka에서 하나의 토픽에 저장된 데이터로 간주되며, 프로듀서로부터 컨슈머로의 하나의 데이터 흐름을 나타낸다.
프로듀서와 컨슈머
시스템의 사용자인 카프카 클라이언트는, 프로듀서 & 컨슈머 두 가지 종류를 가지고 있다.
프로듀서
- Publisher, Writer
- 새로운 메시지를 생성한다.
- 특정한 토픽에 생성된다.
- 기본적으로 프로듀서는 메시지를 작성할 때, 토픽에 속한 파티션들에 RoundRobbin으로 메시지를 쓰게 된다.(Partitioner를 통해 특정 파티션을 지정하여 메시지 작성할 수도 있다.)
컨슈머
- Subscriber, Reader
- 1개 이상의 토픽을 구독해서, 저장된 메시지를 각 파티션에 쓰인 순서대로 읽는다.
- offset을 기록함으로써, 어느 메시지까지 읽었는지 유지한다.
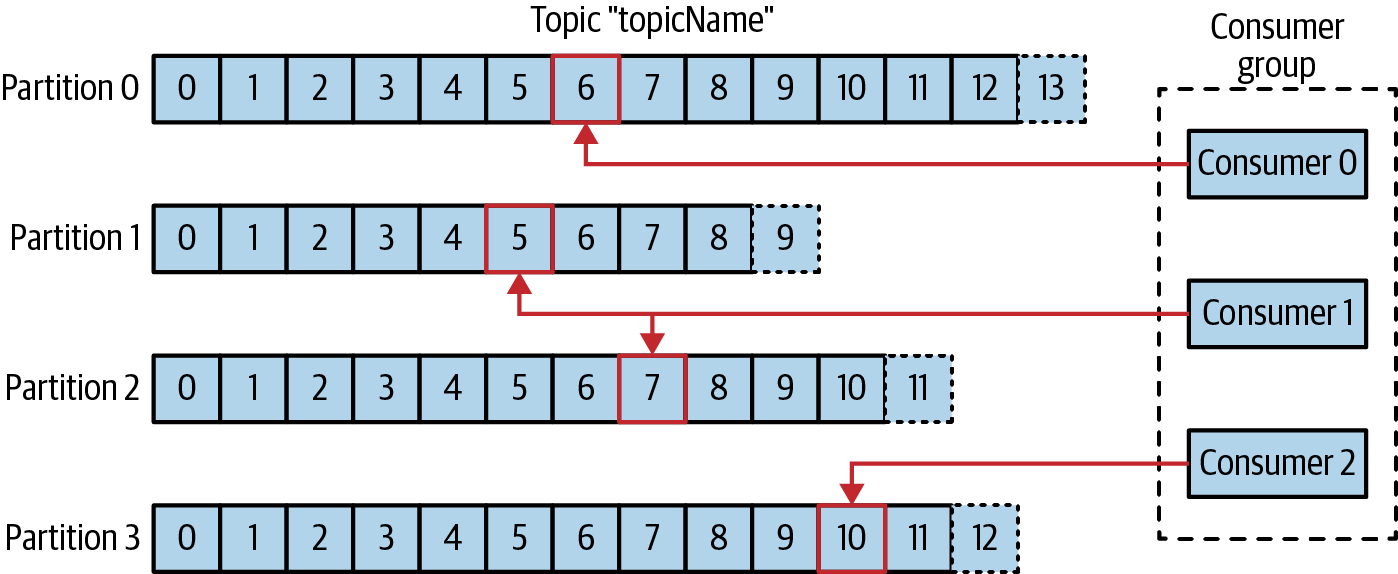
컨슈머 그룹
컨슈머는 Consumer Group의 일원으로서 작동하며 하나 이상의 컨슈머로 구성한다.
컨슈머 그룹은 각 파티션이 하나의 컨슈머에 의해서만 읽히도록 한다. 아래의 그림은 하나의 컨슈머 그룹에 속한 3개의 컨슈머가 하나의 토픽에서 데이터를 읽어오는 모습을 보여준다.
컨슈머를 수평 확장 할 수 있다. 한 컨슈머에 장애가 발생하더라도, 다른 컨슈머가 장애가 난 컨슈머가 읽고 있던 파티션을 재할당받은 뒤 이어서 데이터를 읽을 수 있다.
브로커와 클러스터
브로커
하나의 카프카 서버를 broker라고 부른다. 프로듀서로부터 메시지를 전달받아 오프셋을 할당한 뒤 디스크 저장소에 쓴다. 컨슈머의 파티션 fetch 요청에 응답하여 메시지를 전달한다.
클러스터
broker는 Cluster의 일부로 작동하도록 설계되었다. 하나의 클러스터 안에 n개의 broker가 포함된다. 브로커 중 하나가 Cluster Controller 역할을 한다. (Cluster Controller는 broker중 자동으로 하나가 선정된다.)
Cluster Controller는 파티션을 broker에 할당해주거나, 장애가 발생한 broker를 모니터링하는 등의 작업을 수행한다.
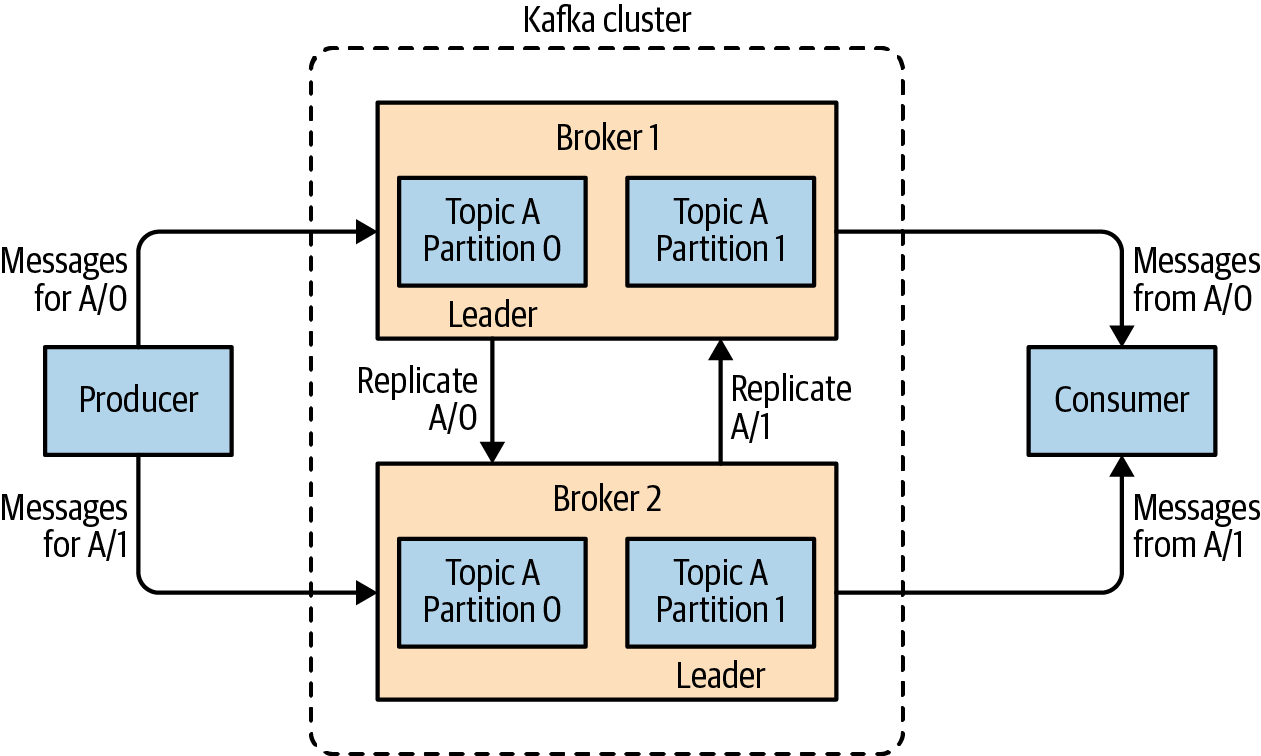
카프카는 내부적으로 Leader와 Follower로 구분하고 각자의 역할을 분담시킵니다.
Leader는 리플리케이션중에서 하나가 선정되며 모든 읽기와 쓰기는 그 리더를 통해서만 가능합니다. 복제된 파티션을 가지고 있는 브로커들을 Follower라고 하며, Follower들은 Leader가 이슈가 있을 경우를 대비해 언제든지 새로운 Leader가 될 준비를 합니다.
지속적으로 새로운 메시지를 확인하고 새로운 메시지가 있으면 Leader로부터 메시지를 복제합니다.
왜 카프카인가?
이 책에서는 카프카가 좋은 이유를 아래처럼 설명하고 있다.
다중 프로듀서
한 토픽에 대해 여러 프로듀서가 메시지를 생성할 수 있다.다중 컨슈머
여러 컨슈머가 상호 간섭 없이 어떠한 메시지도 읽을 수 있다. 다른 메시지큐 서비스와 달리, 컨슈머 단위가 아닌 컨슈머 그룹 단위로 메시지가 소비된다.디스크 기반 보존
메시지를 지속성 있게 저장할 수 있다(메시지가 삭제되는 것이 아니다.) 토픽별로 보존 정책을 지정할 수 있다. 중간에 컨슈머가 중단되었다가 다시 시작하더라도 유실없이 데이터 처리가 가능하다.확장성
유연한 확장성 덕분에 어떠한 크기의 데이터도 처리할 수 있다. 클러스터 작동 중에도 시스템 중단 없이 확장 가능하다.고성능
프로듀서, 컨슈머, 브로커 모두 매우 큰 메시지 스트림을 쉽게 다룰 수 있도록 수평적으로 확장될 수 있다.플랫폼 기능
여러 API와 라이브러리 형태를 제공한다.
[출처]
https://jack-vanlightly.com/blog/2018/9/2/
rabbitmq-vs-kafka-part-6-fault-tolerance-and-high-availability-with-kafka