카프카핵심가이드 4장 - 카프카 컨슈머:카프카에서 데이터 읽기
카프카 핵심가이드 책을 읽은 내용 정리
카프카 컨슈머: 개념
카프카에서 데이터를 읽는 애플리케이션은 토픽을 구독하고 구독한 토픽들로부터 메시지를 받기위해 KafkaConsumer를 사용한다.
카프카로 부터 데이터를 읽어 오는 방법을 이해하기 위해 컨슈머와 컨슈머 그룹을 이해
컨슈머와 컨슈머 그룹
컨슈머
카프카 토픽으로부터 메시지를 읽는 역할
각 파티션(partition)에서 데이터를 읽어올 수 있으며, 특정 오프셋(offset)에서부터 시작해 순차적으로 데이터를 처리컨슈머 그룹
여러 컨슈머로 구성된 그룹을 의미하며, 주로 확장성과 데이터 병렬 처리를 위해 사용됨
각 컨슈머는 그룹 내에서 고유한 파티션을 할당받아 데이터를 처리하며, 동일한 그룹의 컨슈머는 동일한 데이터를 중복으로 소비하지 않음
컨슈머 그룹을 사용하면 애플리케이션이 특정 파티션에서 데이터 병렬 처리가 가능하고, 하나의 컨슈머가 실패할 경우 다른 컨슈머가 해당 파티션을 이어받아 처리할 수 있음
컨슈머 그룹과 컨슈머에 대한 이해
4개의 파티션을 가지는 토픽 T1이 있다고 가정
컨슈머가 1개 밖에 없다면, C1이 모든 메시지를 받게 됨
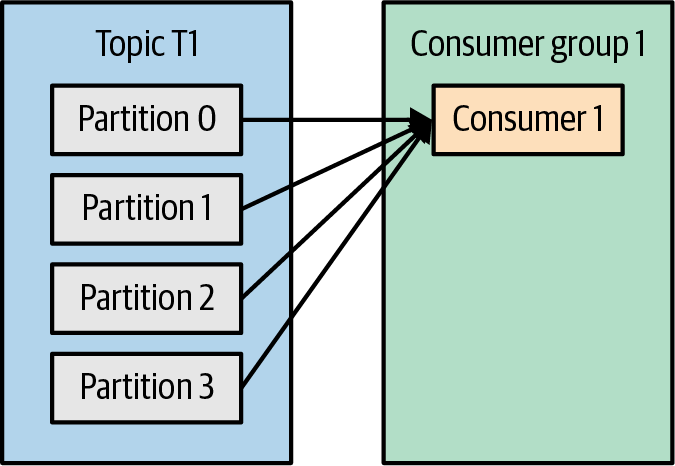
컨슈머가 1개 추가 되어 2개가 된다면, 각각 2개의 파티션에서 메시지를 받을 수 있음
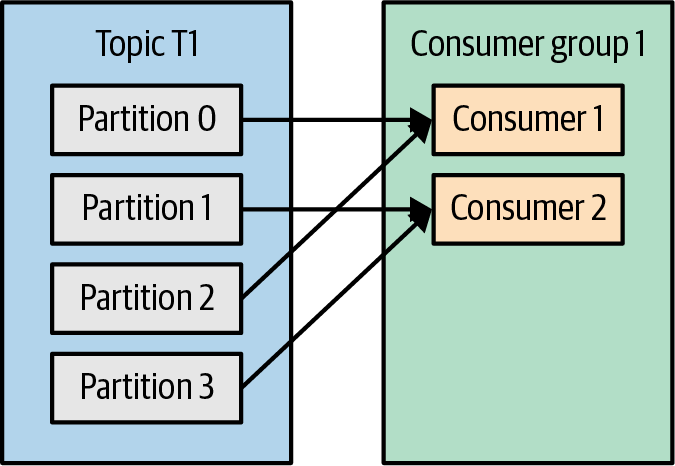
컨슈머가 4개가 있다면 각각 하나의 파티션에서 메시지를 읽어 오게 됨
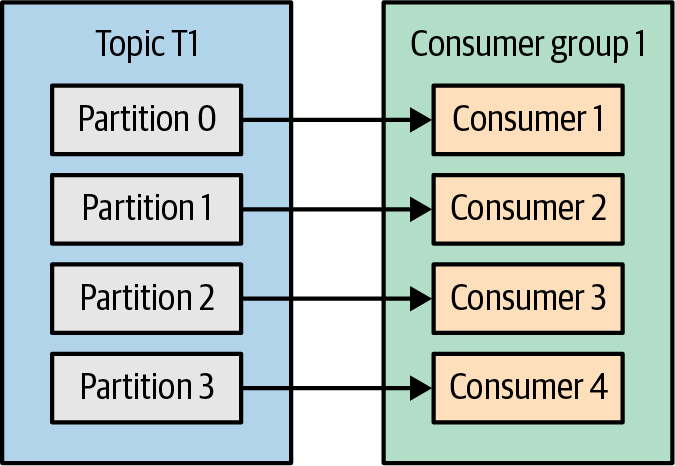
파티션의 개수보다 컨슈머가 더 많은 경우에는 유휴 컨슈머가 발생하게 됨
=> 토픽에 설정된 파티션 수 이상으로 컨슈머를 투입하는 것은 아무 의미가 없게됨.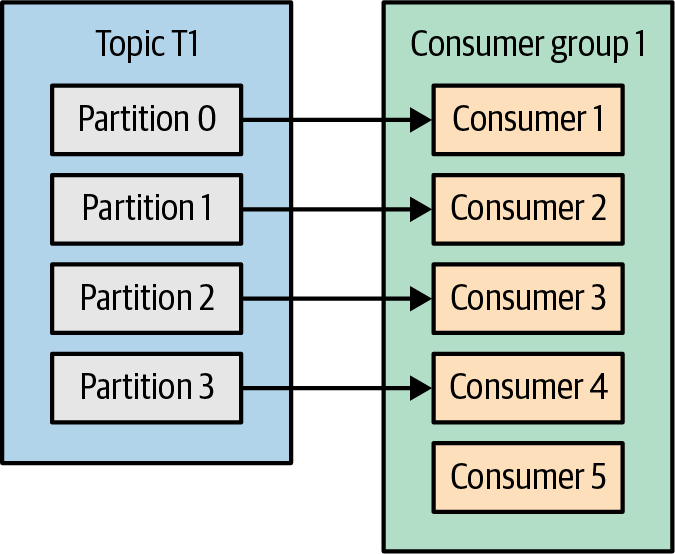
한 어플리케이션의 규모를 확장하기 위해 컨슈머 수를 늘리는 경우 외에도 여러 어플리케이션이 동일한 토픽에서 데이터를 읽어와야 하는 경우에는 아래와 같이 새로운 컨슈머 그룹을 만들면 됨
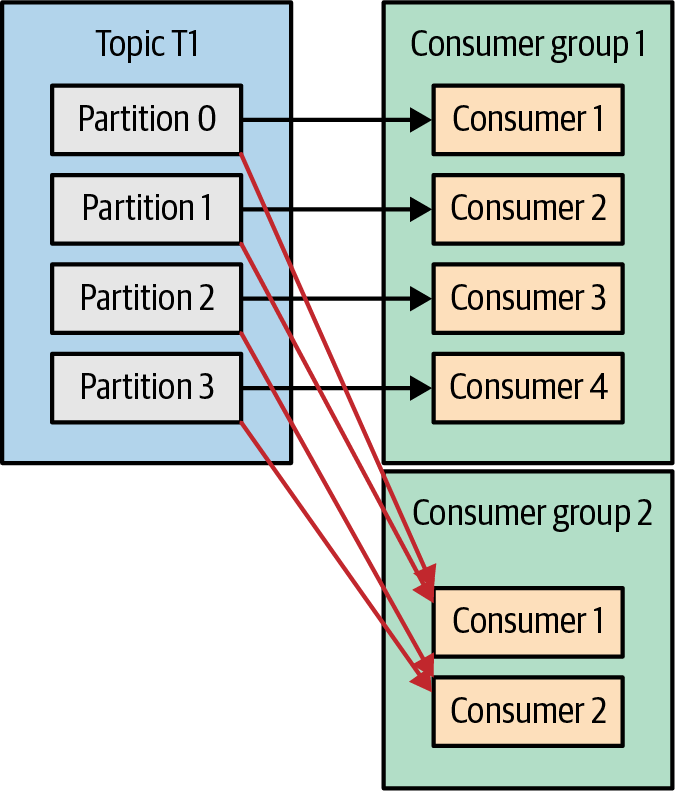
1개 이상의 토픽에 대해 모든 메시지를 받아야 하는 애플리케이션별로 새로운 컨슈머 그룹을 생성
토픽에서 메시지를 읽거나 처리하는 규모를 확장하기 위해서는 이미 존재하는 컨슈머 그룹에 새로운 컨슈머를 추가함으로써 해당 그룹 내의 컨슈머 각각이 메시지의 일부만을 받아서 처리하도록함
컨슈머 그룹과 파티션 리밸런스
- 리밸런스
컨슈머에 할당된 파티션을 다른 컨슈머에게 할당해주는 작업으로 높은 가용성(high availability)와 규모 가변성(scalability)을 제공
조급한 리밸런스
모든 파티션 할당을 해제한 뒤, 다시 파티션을 할당 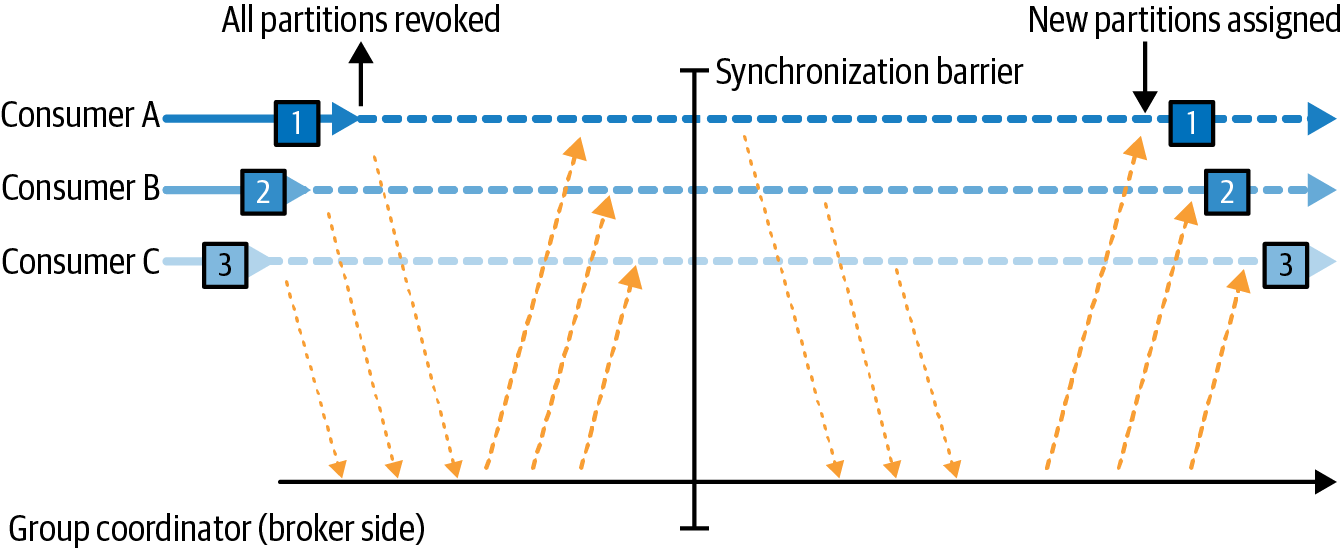
협력적 리밸런스
점진적 리밸런스(Increamental rebalance)라고도 하며 Kafka 3.1부터 Default
한 컨슈머에 할당된 파티션만을 다른 파티션에게 재할당. 이 재할당에 포함되지 않는 파티션과 그 컨슈머는 영향을 받지 않음
아래와 같은 단계로 실행
- 컨슈머 그룹 리더가 컨슈머에게 특정 파티션이 재 할당 될 것을 통보
- 컨슈머는 해당 파티션에서 데이터를 읽어오는 작업을 중지하고, 파티션에 대한 소유권을 포기
- 컨슈머 그룹 리더가 소유권이 없어진 파티션을 재할당
- 위 과정을 안정적으로 파티션이 할당될 때 까지 반복
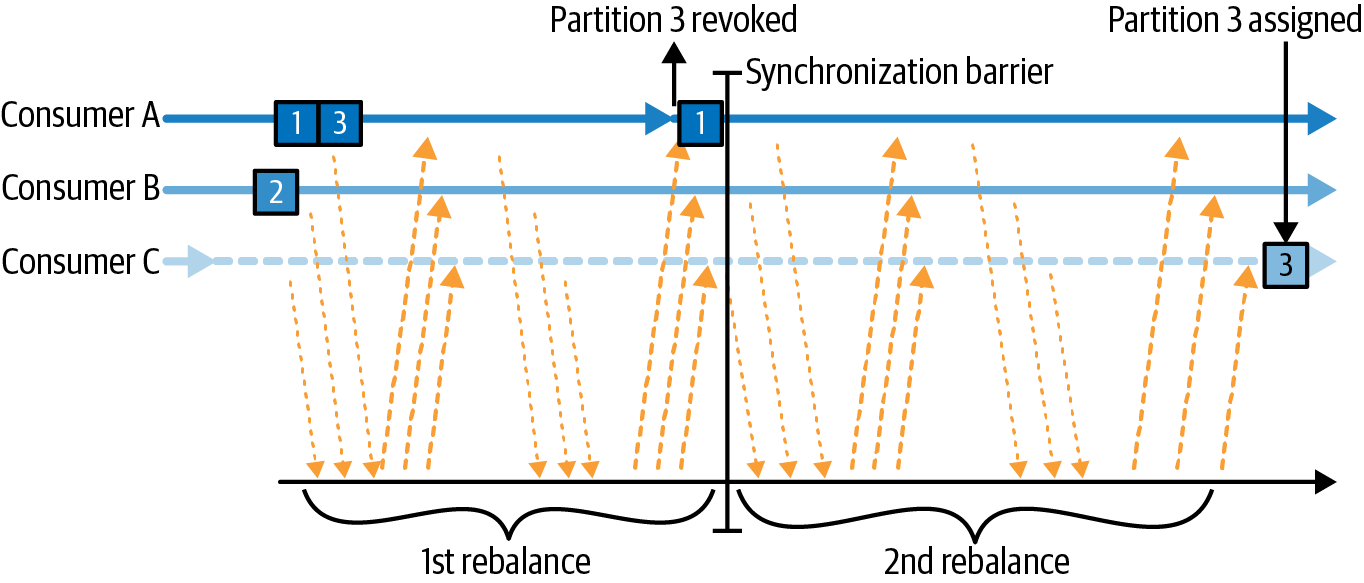
컨슈머 그룹에는 그룹 코디네이터(Group coordinator)에 하트비트(Hearbeat)를 전송함으로써 멤버십과 할당된 파티션에 대한 소유권을 유지
그룹 코디네이터는 정해진 시간 동안 하트비트가 오지 않을 경우 컨슈머가 죽었다고 판단한 후 리밸런스를 수행
그룹코디네이터란?
컨슈머 그룹의 상태를 관리하고 조정하며 아래와 같은 역할을 수행하는 브로커
- 컨슈머 그룹의 조정(리밸런싱)
그룹 내 컨슈머가 연결되거나 연결이 끊길 때, 그룹 코디네이터는 모든 컨슈머에게 각 파티션을 어떻게 할당할지 결정하고 재조정- 오프셋 관리
그룹 코디네이터는 컨슈머가 처리한 메시지의 오프셋을 주기적으로 기록하며 이를 통해 컨슈머가 재시작하거나 장애 발생 시, 마지막으로 처리한 위치부터 데이터를 다시 처리할 수 있음- 컨슈머의 생존 확인
컨슈머는 주기적으로 하트비트(heartbeat)를 그룹 코디네이터에 보냄으로써 그룹 코디네이터는 각 컨슈머가 정상적으로 작동하고 있는지 확인
만약 하트비트가 일정 시간 동안 오지 않으면 해당 컨슈머가 종료된 것으로 간주하고 리밸런싱을 수행하여 다른 컨슈머가 그 역할을 이어받도록 함
컨슈머 그룹 리더는 단순히 컨슈머 중 가장 먼저 join한 컨슈머가 된다. => 컨슈머
코디네이터는 kafka 서버 노드 중 하나이다. => 브로커(노드)
정적 그룹 멤버십
기본적으로 컨슈머가 갖는 멤버십은 일시적인데 이는 그룹을 떠나는 순간 해당 컨슈머에 할당된 파티션을 해제되고, 다시 참여하면 리밸런스를 통해 다시 파티션을 할당 받음
Group.instance.id 값을 설정 해 주는 경우, 컨슈머가 일시적인 멤버십이 아닌 정적인 멤버가 될 수 있음
컨슈머가 꺼지는 경우, 컨슈머 그룹을 자동으로 떠나지 않음.
다시 그룹에 조인시 기존 파티션을 할당 받음(코디네이터가 id별로 다 캐싱하고 있음)
동일한 Group.instance.id를 가지는 컨슈머는 존재 할 수 없음(그룹 조인 시 에러)
Session.timeout.ms 동안 조인하지 않을 시 리밸런싱 됨
카프카 컨슈머 생성하기
반드시 지정해야하는 속성은 bootstrap.servers, key.deserializer, value.deserializer
bootstrap.servers
카프카 클러스터로의 연결 문자열key.deserializer
메시지의 key값 바이트 배열을 자바 객체로 변환하는 클래스를 지정value.deserializer
메시지의 value값 바이트 배열을 자바 객체로 변환하는 클래스를 지정
- KafkaConsumer 생성 방법
1 2 3 4 5 6
Properties props = new Properties(); props.put("bootstrap.servers", "broker1:9092,broker2:9092"); props.put("group.id", "CountryCounter"); props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
토픽 구독하기
컨슈머를 생성하고 나서는 다음으로 할 일은 1개 이상의 토픽을 구독하는 것이다.
- 하나의 토픽 이름(customerCountries)만으로 목록 생성
1
consumer.subscribe(Collections.singletonList("customerCountires"));
- 정규식을 사용해서 토픽 구독
1
consumer.subscribe(Pattern.compile("test.*"));
폴링 루프
- 폴링루프 컨슈머 중요 코드
서버에 추가 데이터가 들어왔는지 폴링하는 단순한 루프1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Duration timeout = Duration.ofMillis(100); while (true) { ConsumerRecords<String, String> records = consumer.poll(timeout); for (ConsumerRecord<String, String> record : records) { System.out.printf("topic = %s, partition = %d, offset = %d, " + "customer = %s, country = %s\n", record.topic(), record.partition(), record.offset(), record.key(), record.value()); int updatedCount = 1; if (custCountryMap.containsKey(record.value())) { updatedCount = custCountryMap.get(record.value()) + 1; } custCountryMap.put(record.value(), updatedCount); JSONObject json = new JSONObject(custCountryMap); System.out.println(json.toString()); } }
스레드 안전성
하나의 스레드에서 동일한 그룹 내에 여러개의 컨슈머를 생성할 수 없으며, 같은 컨슈머를 다수의 스레드가 안전하게 사용할 수도 없음
즉, 하나의 스레드당 하나의 컨슈머
컨슈머 설정하기
대부분의 설정은 default 설정값을 가지고 있으므로 딱히 변경할 필요는 없지만 컨슈머의 성능과 가용성에 영향을 주는 상대적으로 중여한 속성들을 소개
fetch.min.bytes
컨슈머가 브로커로부터 레코드를 얻어올 때 받는 데이터의 최소량
일정시간동안 어느정도는 채워서 보내야되는지에대한 기준
fetch.max.wait.ms
카프카가 컨슈머에게 응답하기 전 충분한 데이터가 모일 때 까지 얼마나 기다리게 할건지에 대한 설정
fetch.max.bytes
최대 바이트 수. 컨슈머가 브로커를 폴링할 때 카프카가 리턴하는 최대 바이트 수 를 지정
max.poll.records
poll()을 호출할 때마다 리턴되는 최대 레코드 수를 지정
max.parition.fetch.bytes
서버가 파티션별로 리턴하는 최대 바이트 수를 결정
session.timeout.ms 그리고 heartbeat.interval.ms
하트비트를 얼마나의 주기로 보낼것인지, 타임아웃은 어느정도 하트비트가 오지 않으면 죽었다고 볼 것인지에 대한 설정
heartbeat.interval.ms는 session.timeout.ms보다 더 낮은 값이어야하며 대체로 1/3으로 결정하는 것이 보통
ex) 하트비트 3초, timeout 9초 로 설정 할 경우 심장이 3번 안뛰면 죽었다고 판단.
카프카 2.8에서는
session.timeout.ms기본값이 10초 였지만, 3.0부터는 기본값이 45초로 변경됨
max.pol.interval.ms
컨슈머가 폴링을 하지 않고도 죽은 것으로 판정되지 않을 수 있는 최대 시간을 지정
카프카는 하트비트만 보고 죽은 컨슈머를 판단하지 않고, 이 설정값 만큼의 시간동안 폴링하지않으면 죽었다고 판단
컨슈머가 여전히 레코드를 처리하고 있는지의 여부를 확인하는 가장 쉬운 방법은 컨슈머가 추가로 메시지를 요청하는지를 확인하는 것
default.api.timeout.ms
API를 호추할 때 명시적인 타임아웃을 지정하지 않는 한, 거의 모든 컨슈머 API 호출에 적용되는 타임아웃 값
request.timeout.ms
컨슈머가 브로커로부터의 응답을 기다릴 수 있는 최대 시간
auto.offset.reset
컨슈머가 예전에 오프셋을 커밋한 적이 없거나, 커밋된 오프셋이 유효하지 않을 때(대개 컨슈머가 오랫동안 읽은 적이 없어서 오프셋의 레코드가 이미 브로커에서 삭제된 경우), 파티션을 읽기 시작할 때의 동작을 정의
latest: 가장 최신 레코드 부터 읽기earliest: 파티션의 맨 처음부터 모든 데이터를 읽기
enable.auto.commit
컨슈머가 자동으로 오프셋을 커밋할지의 여부. 기본값은 true
partition.assignment.strategy
컨슈머에게 어느 파티션이 할당될지를 결정하는 역활
range
roundrobin
sticky
cooperative sticky
client.id
브로커가 요청을 보낸 클라이언트를 식별하는데 사용
metrcis, logging 등에서 사용
client.rack
서버 렉 설정
group.instance.id
컨슈머에 정적 그룹 멤버십 기능을 적용하는 설정
receive.buffer.bytes, send.buffer.bytes
데이터를 읽거나 쓸 때 소켓이 사용하는 TCP의 수신 및 수신 버퍼 크기 설정
offsets.retention.minutes
이 옵션은 컨슈머 그룹이 더 이상 메시지를 읽지 않는 경우, 해당 그룹의 오프셋 정보(현재 읽고 있는 위치)를 얼마나 오랫동안 유지할지를 결정
오프셋과 커밋
- 오프셋 커밋
파티션에서의 현재 위치를 업데이트 하는 작업.
poll()이 리턴한 마지막 오프셋 바로 다음 오프셋을 커밋하는 것이 기본 작동
카프카는 전통적인 메시지 큐와는 다르게 레코드를 개별적으로 커밋하지 않고, 컨슈머는 파티션에서 성공적으로 처리해 낸 마지막 메시지를 커밋함으로써 그 앞의 모든 메시지들 역시 성공적으로 처리되었을 암묵적으로 나타냄
카프카에 특수 토픽인 __consumer_offsets 토픽에 각 파티션별로 커밋된 오프셋을 업데이트 하도록 하는 메시지를 보냄으로써 컨슈머는 오프셋을 커밋함
메시지가 중복처리 되는 경우
커밋된 오프셋 < 클라이언트가 처리한 마지막 메시지의 오프셋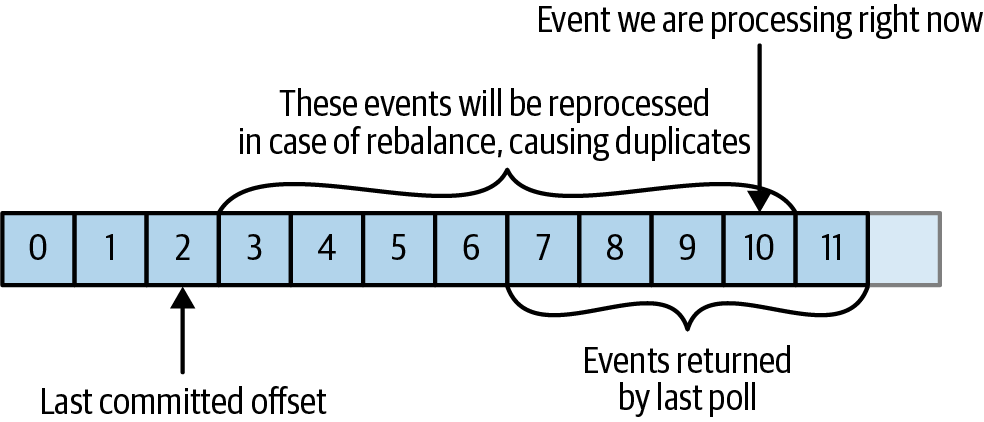
메시지가 누락되는 경우
커밋된 오프셋 > 클라이언트가 처리한 마지막 메시지의 오프셋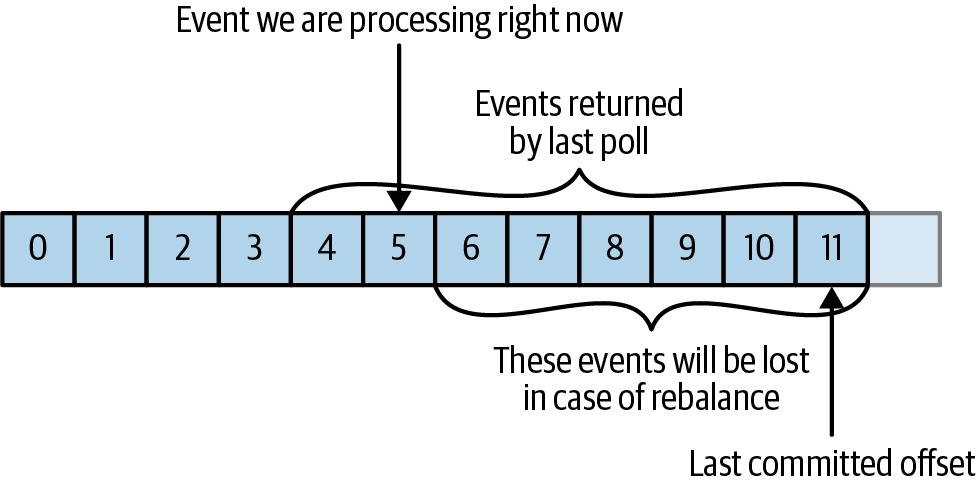
자동 커밋
enable.auto.commit=true로 설정하면 5초에 한 번, poll()을 통해 받은 메시지 중 마지막 메시지의 오프셋을 커밋
자동 커밋은 폴링 루프에 의해서 실행됨
poll()을 실행할 때마다 컨슈머는 커밋해야하는지를 확인한 뒤 마지막 poll() 호출에서 리턴된 오프셋을 커밋
매우 편리하긴하나 개발자가 중복 메시지를 방지하기엔 충분하지 않음
현재 오프셋 커밋하기
메시지 중복 처리, 메시지 누락을 줄이기 위해서는 개발자들은 오프셋이 커밋되는 시각을 제어하고자함
enable.auto.commit=false로 설정 후 명시적으로 커밋하려 할 때만 오프셋이 커밋되게 할 수 있음 => commitSync() 명령을 통해 가능
commitSync()는 poll()에 의해 리턴된 마지막 오프셋을 커밋
commitSync()의 호출을 언제 하느냐에 따라 메시지 중복 처리, 메시지 누락의 가능성이 존재
- 가장 최근의 메시지 배치를 처리한 뒤 오프셋을 커밋하는 예제
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Duration timeout = Duration.ofMillis(100); while (true) { ConsumerRecords<String, String> records = consumer.poll(timeout); for (ConsumerRecord<String, String> record : records) { System.out.printf("topic = %s, partition = %d, offset = %d, customer = %s, country = %s\n", record.topic(), record.partition(), record.offset(), record.key(), record.value()); } try { consumer.commitSync(); } catch (CommitFailedException e) { log.error("commit failed", e) } }
비동기적 커밋
commitSync()는 브로커가 응답할 때까지 어플리케이션이 블록됨
비동기적 커밋 브로커가 응답할 때까지 기다리지 않음
- 단순한 비동기적 커밋 예제
1 2 3 4 5 6 7 8 9 10 11
Duration timeout = Duration.ofMillis(100); while (true) { ConsumerRecords<String, String> records = consumer.poll(timeout); for (ConsumerRecord<String, String> record : records) { System.out.printf("topic = %s, partition = %s, offset = %d, customer = %s, country = %s\n", record.topic(), record.partition(), record.offset(), record.key(), record.value()); } consumer.commitAsync(); }
위 방식의 단점은 실패하더라도 재시도하지 않는다는 점
왜냐하면 그 다음번 commitAsync가 커밋을 성공했을수도 있기 때문
- 오프셋 값 비교를 통해 재시도를 하는 비동기적 커밋 예제
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Duration timeout = Duration.ofMillis(100); while (true) { ConsumerRecords<String, String> records = consumer.poll(timeout); for (ConsumerRecord<String, String> record : records) { System.out.printf("topic = %s, partition = %s, offset = %d, customer = %s, country = %s\n", record.topic(), record.partition(), record.offset(), record.key(), record.value()); } consumer.commitAsync(new OffsetCommitCallback() { public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception e) { if (e != null) log.error("Commit failed for offsets {}", offsets, e); // 여기서 재시도 } }); }
동기적 커밋과 비동기적 커밋을 함께 사용하기
대체로, 재시도 없는 커밋이 실패하더라도 큰 문제가 발생하지 않음.
그러나 컨슈머를 닫기 전 혹은 리밸런스 전 마지막 커밋이라면 문제 => 성공 여부를 추가호 확인할 필요 O
일반적인 패턴은 종료 직전 commitAsync()와 commitSycn()를 함께 사용하는 것
- commitAsync()와 commitSycn()를 함께 사용하는 예제
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Duration timeout = Duration.ofMillis(100); try { while (!closing) { ConsumerRecords<String, String> records = consumer.poll(timeout); for (ConsumerRecord<String, String> record : records) { System.out.printf("topic = %s, partition = %s, offset = %d, customer = %s, country = %s\n", record.topic(), record.partition(), record.offset(), record.key(), record.value()); } consumer.commitAsync(); } consumer.commitSync();//while문에서 closing이 true가 되는 상황에서만 실행 } catch (Exception e) { log.error("Unexpected error", e); } finally { consumer.close(); }
특정 오프셋 커밋하기
poll()이 엄청나게 큰 배치를 리턴한 경우, 중간중간에 커밋을 하고 싶을 때 사용 가능
- 특정 오프셋을 커밋하는 예
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
private Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>(); int count = 0; .... Duration timeout = Duration.ofMillis(100); while (true) { ConsumerRecords<String, String> records = consumer.poll(timeout); for (ConsumerRecord<String, String> record : records) { System.out.printf("topic = %s, partition = %s, offset = %d, customer = %s, country = %s\n", record.topic(), record.partition(), record.offset(), record.key(), record.value()); currentOffsets.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1, "no metadata")); if (count % 1000 == 0) { consumer.commitAsync(currentOffsets, null); // 커밋 } count++; } }
리밸런스리스너
컨슈머 API는 컨슈머에 파티션이 할당되거나 해제될 때 리스너를 통해 코드를 실행 할 수 있는 기능을 제공
책에서는 일반적인 상황(조급한 리밸런스)라고 말하지만, 3.1버전 이후에서 일반적인 상황은 협력적 리밸런스
onPartitionsAssigned
파티션이 컨슈머에게 재할당된 후, 컨슈머가 메세지를 읽기 시작하기 전에 호출
오프셋 탐색 등과 같은 준비작업을 수행
poll.timeout.ms내에 모든 작업이 끝나야함onPartitionsRevoked
컨슈머가 할당받았던 파티션이 할당 해제될떄 호출(리밸런스 때문 수도, 컨슈머가 닫혀서 그럴 수도)- 조급한 리밸런스: 컨슈머가 메세지 읽기를 멈춘 뒤, 리밸런스가 시작되기 전에 호출
- 협력적 리밸런스: 리밸런스가 완료 될 때, 컨슈머에게서 할당 해제되어야 할 파티션들에 대해서만 호출
여기서 오프셋을 커밋해주어야함
onPartitionsLost
- 조급한 리밸런스: onPartitionsRevoked가 실행됨
- 협력적 리밸런스: 당된 파티션이 해제되기 전에 다른 컨슈머에게 할당이된 예외적인 상황에서 호출(오프셋 커밋 같은 작업에 주의해야함)
특정 오프셋의 레코드 읽어오기
파티션의 맨 앞부터, 앞의 메시지를 전부 건너뛰고, 파티션에 새로 들어온 메시지부터 읽거나, 특정한 오프셋으로 탐색해 갈 수도 있음
- 모든 파티션의 현재 오프셋을 특정한 시각에 생성된 레코드의 오프셋으로 설정하는 방법
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Long oneHourEarlier = Instant.now().atZone(ZoneId.systemDefault()).minusHours(1).toEpochSecond(); // 이 컨슈머에 할당된 모든 파티션에 대해 컨슈머를 되돌리고자 하는 타임스탬프 값을 담음 Map<TopicPartition, Long> partitionTimestampMap = consumer.assignment() .stream() .collect(Collectors.toMap(tp -> tp, tp -> oneHourEarlier)); // 각 타임스탬프에 해당하는 오프셋을 받아옴 Map<TopicPartition, OffsetAndTimestamp> offsetMap = consumer.offsetsForTimes(partitionTimestampMap); // 오프셋을 재설정 for(Map.Entry<TopicPartition,OffsetAndTimestamp> entry: offsetMap.entrySet()) { consumer.seek(entry.getKey(), entry.getValue().offset()); }
폴링 루프를 벗어나는 방법
컨슈머를 종료하고자 할 때 컨슈머가 poll()을 오랫동안 기다리고 있더라도 즉시 탈출하고 싶다면 다른 스레드에서 consumer.wakeup()을 호출
consumer.wakeup()을 호출하면 poll()이 WakeupException을 발생시키며 중단되거나, 대기중이 아닐 경우에는 다음 번에 처음으로 poll()가 호출될 때 예외가 발생함.
WakeupException은 별도의 예외처리를 해줄 필요는 없지만 스레드를 종료하기 전 consumer.close()를 호출해야함
consumer.close()를 하지 않으면 세션 타임아웃을 기다려야함
디시리얼라이저
카프카로부터 받은 바이트 배열을 자바 객체로 변환하기 위해 deserializer가 필요
커스텀 디시리얼라이저
Avro 디시리얼라이저 사용하기
독립 실행 컨슈머: 컨슈머 그룹없이 컨슈머를 사용해야 하는 이유와 방법
컨슈머 그룹 없이 컨슈머를 사용하는 경우는 다음과 같이 정의할 수 있음
- 하나의 컨슈머가 모든 파티션으로부터 모든 데이터를 읽어와야 하는 경우
- 토픽의 특정 파티션으로부터 데이터를 읽어와야 하는 경우
=> 이러한 경우는 컨슈머 그룹이나 리밸런스 기능이 불필요!! => 단순히 컨슈머에게 특정한 토픽과 파티션을 할당해주고, 메시지를 읽어서 처리하고 오프셋을 커밋만 해주면 되는것..!
요약
여러 컨슈머들이 토픽에서 이벤트를 나눠서 읽어올 수 있게 하는지 설명함