카프카핵심가이드 8장 - "정확히 한 번" 의미 구조
카프카 핵심가이드 책을 읽은 내용 정리
“정확히 한 번”
even if a producer retries sending a message, it leads to the message being delivered exactly once to the end consumer.
⇒ producer가 메시지 전송을 다시 시도하더라도 메시지는 최종 consumer에게 정확히 한 번만 전달된다. (더보기)
message delivery semantic
A지점에서 B지점으로 데이터를 전송할 때 어느 만큼의 신뢰도로 데이터를 전송하는지에 대한 정의 ⇒ 데이터 전달 신뢰도
적어도 한번(at least once)
데이터가 전달될 때 유실이 발생하지는 않지만 중복이 발생할 가능성이 있음을 의미. 카프카 기본 옵션을 사용할 경우 “적어도 한번을 보장”
많아도 한번(at most once)
최대 한번의 메시지를 보내고 일부 데이터는 유실될 수 있음을 의미.
정확히 한번(exactly once)
A에서 B로 데이터를 보낼 때 어떠한 경우에서도 유실이나 중복이 발생하지 않는 것을 의미.
kafka에서 “정확히 한번”을 지키는 방법
멱등적 프로듀서와 트랜잭션으로 kafka는 “정확히 한번”을 지킬 수 있다.
1. 멱등적 프로듀서
- 멱등적(idempotence) : 동일한 작업을 여러 번 실행한 것과 결과가 동일하다라는 의미
멱등적 프로듀서의 동작원리
멱등적 프로듀서 기능을 켜면
모든 메시지는 고유한 프로듀서 ID, 시퀀스 넘버를 가지게됨브로커는 이 값과 토픽 및 파티션을 조합하여 고유한 식별자로 사용하며, 파티션별로 쓰여진 마지막 5개의 메시지들을 추적하는 데에 사용 (5개는 기본값이며 max.in.flights.requests.per.connection 값을 통해 변경할 수 있음)
- 예전에 받은 적 있는 메시지를 받을 경우, 에러 발생시켜 중복 메시지를 거부
- 똑같은 식별자를 가진 메시지를 받으면 적절한 에러를 발생시키고, 시퀀스 넘버가 예상보다 크게 올 경우에도 에러(out of order sequence number)를 발생시킴
‘out of order sequence number’가 발생한 후에도 프로듀서가 정상 작동 한다면, 프로듀서와 브로커 사이에 메시지 유실이 있음을 의미. ex) 2번 받고 27번 받으면, 3~26의 메시지들에는 무슨 일이 발생한것.
- 프로듀서 재시작
- 프로듀서에 장애가 발생할 경우, 새 프로듀서를 생성하여 장애가 난 프로듀서를 대체
- 멱등적 프로듀서기능이 켜져있을 경우, 카프카 브로커로부터 프로듀서 ID를 생성받음.
- 트랜잭션 기능을 켜지 않았을 경우, 프로듀서를 초기화할 때마다 새 ID가 생성됨
- 메시지 중복을 피할 수 없다.
- 프로듀서에 장애가 발생하여 대신 투입된 새 프로듀서가 기존 프로듀서가 이미 전송한 메시지를 다시 전송할 경우, 브로커는 메시지 중복을 알아차리지 못한다. (두 메시지는 다른 프로듀서 ID, 시퀀스를 갖기 때문에 다르게 취급된다.)
- 기존 프로듀서가 작동을 멈췄다가 새 프로듀서가 투입된 뒤 작동을 재개해도 마찬가지로 메시지 중복을 알아차리지 못한다.
좀비란?
스스로가 죽인 상태인지 모르는 컨슈머를 좀비라고 부른다. - 브로커 장애
- 브로커 장애가 발생할 경우, 컨트롤러는 장애가 난 브로커가 리더를 맡고 있었던 파티션들에 대해 새 리더 선출
- 리더는 새 메시지가 쓰여질 때마다 인-메모리 프로듀서 상태에 저장된 최근 5개의 시퀀스 넘버를 업데이트 ⇒ 팔로워 레플리카는 리더로부터 새로운 메시지를 복제할 때마다 자체적인 인-메모리 버퍼를 업데이트 ⇒ 파티션 리더가 속한 브로커에서 장애가 발생해도 다음 리더가 될 파티션이 속한 브로커에서도 메시지는 최신 상태를 유지가능 ⇒ 문제 없음
- 장애가 발생한 기존 리더가 복구되어 재시작 하더라도, 브로커가 종료될때, 새 세그먼트가 생성될 때마다의 프로듀서 상태에 대한 스냅샷을 파일로 저장함. ⇒ 프로듀서상태를 최신상태로 복구할 수 있음
멱등적 프로듀서의 한계
- 프로듀서의 내부 로직으로 인한 재시도가 발생한 경우 생기는 중복만 방지 producer.send 메서드로 동일한 메시지를 두 번 보내면 프로듀서가 동일한 메시지인지 알 방법이 없으므로 중복이 발생하게 됨
- 멱등적 프로듀서는 프로듀서 자체의 재시도 메커니즘(프로듀서, 네트워크, 브로커 에러로 인해 발생하는)에 의한 중복만 방지
멱등적 프로듀서 사용법
- 프로듀서에
enable.idempotence=true를 설정(kafka 3.0부터는 default) - acks=all 설정일 경우 성능 차이가 없음
2. 트랜잭션
카프카 스트림즈를 통해 데이터 스트림을 처리하는 애플리케이션에서 정확히 한 번을 보장하기 위해 도입.
읽기-처리-쓰기 패턴에서 사용하도록 개발되었다. ⇒ “정확히 한 번”의미 구조 보장
읽기-처리-쓰기 패턴이란?
어떤 토픽에서 데이터를 읽어와 애플리케이션에서 데이터를 처리하고, 결과를 다시 출력 토픽에 쓰는 패턴
트랜잭션 활용 사례
정확성이 중요한 스트림 처리 어플리케이션에 유용함.
예시) 금융 어플리케이션…
트랜잭션이 해결하는 문제
애플리케이션 크래시로 인한 재처리
메시지를 읽은 애플리케이션은
1)결과를 출력 토픽에 쓰고,2)읽어온 메시지의 오프셋을 커밋해야한다.출력 토픽에는 썻는데 입력 오프셋은 커밋되기전 애플리케이션 크래시가 난다면??
⇒ 4장에서 봤듯이 컨슈머는 파티션의 마지막 커밋된 오프셋으로부터 레코드를 다시 읽기 시작
⇒ 마지막 오프셋 ~ 애플리케이션 크래시 시점까지의 메시지는 다시 처리될 것
⇒
중복 발생좀비 애플리케이션에 의해 발생하는 재처리
애플리케이션이 카프카로부터 레코드 배치를 읽어온 직후 멈추거나 연결이 끊긴다면??
⇒ 4장에서 봤듯이 컨슈머는 파티션의 마지막 커밋된 오프셋으로부터 레코드를 다시 읽기 시작
⇒ 그 사이 멈췄던 애플리케이션 첫번째 인스턴스가 살아난다
⇒ 마지막으로 읽어왔던 레코드 배치를 처리하고 결과를 출력 토픽에 쓴다
⇒
중복 발생
트랜잭션은 어떻게 “정확히 한 번” 을 보장하는가?
“정확히 한번” 처리라는 말은 읽기, 처리, 쓰기 작업이 원자적으로 이루어진다는 것을 의미
⇒ 카프카에서는 읽어온 원본 메시지의 오프셋이 커밋되고 결과가 성공적으로 쓰여지거나, 둘 다 실패한다는 보장이 필요
“정확히 한번을 보장하기 위한 방법”
- 원자적 다수 파티션 쓰기
- 오프셋 커밋과 데이터를 처리해 출력 토픽으로 보내는 일은 모두 파티션에 데이터를 쓰는 것이다. 따라서 이 일들을 원자적으로 수행하면 데이터 처리와 오프셋 커밋의 사이에 발생하는 일을 생각하지 않아도 된다.
- 원자적 다수 파티션 쓰기 기능을 사용하려면 트랜잭션적 프로듀서를 사용해야 한다.
- 트랜잭션적 프로듀서와 일반 프로듀서의 차이점은 별도의 transactional.id 값을 내부에 저장하는 initTransactions() 를 호출했다는 점이다. transactional.id 값은 프로듀서가 멈춰도 유지되어 재시작시 매핑되는 기존 producer.id 를 그대로 사용할 수 있게 해준다.
“데이터를 쓴다” + “커밋을 한다” 이렇게 2번 메시지를 쓰게된다.
- 좀비 펜싱
- 위 문제 2번에서 살펴본 재시작하여 파티션 할당이 해제되었지만 모르고 있는 컨슈머를 좀비라고 부른다. 좀비가 출력 스트림에 결과를 쓰는 것을 막는 것이 좀비 펜싱이다.
- 일반적으로 에포크 방식을 통해 initTransactions() 를 호출하면 transactional.id의 에포크 값을 증가 시켜 높은 에포크 값을 가진 프로듀서의 요청만 처리하는 방식이다.
Fencing이란?
트랜잭션 관리에서 “격리” 또는 “차단”의 의미로 사용 - 컨슈머 격리 수준
- 위에서 살펴본 기능들은 모두 프로듀서의 기능이다. 컨슈머도 격리 수준을 설정하여 정확히 한 번 데이터를 처리할 수 있는 기능이 존재한다.
- isolation.level 설정값을 기본값인 read_uncommitted 로 사용하면 프로듀서가 메시지를 쓰고 트랜잭션을 커밋하지 않아도 해당 메시지를 전부 읽어오지만, read_committed 로 설정하면 프로듀서가 트랜잭션을 커밋해야만 해당하는 메시지들을 읽어올 수 있다.
- 컨슈머의 격리 수준을 높여 정확히 한 번 데이터를 처리하도록 할 수도 있으나, 트랜잭션이 커밋되지 않으면 데이터를 볼 수 없는 만큼 그 시간동안 컨슈머는 데이터를 처리할 수 없어 종단 지연이 길어진다. 데이터 스트림을 처리하는 애플리케이션은 트랜잭션 없이 원자적 다수 파티션 쓰기 기능만으로도 정확히 한 번의 데이터 처리를 보장할 수 있다.
참고.
프로듀서의 트랜잭션이란 데이터베이스 트랜잭션과 같이 트랜잭션 내의 여러 개의 메시지가 한번에 쓰여지거나 롤백되면 전부 없어지는 것을 말한다.
책의 설명에서는 transactional.id 를 사용하는 프로듀서의 기능과 메시지를 쓸 때의 트랜잭션 기능을 모두 트랜잭션이라고 혼용해서 사용하고 있다.
트랜잭션으로 해결할 수 없는 문제
위에서 언급한 “정확히 한번”은 카프카에 대한 쓰기 이외의 작동에서는 보장 안됨
- 스트림 처리에서의 side effect
- 애플리케이션이 파티션에서 데이터를 읽어와 처리하는 과정에서 사용자에게 이메일을 보낸다고 했을 때, 이메일은 애플리케이션에서 전송하는 것이므로 메시지의 커밋, 프로듀서 트랜잭션과는 관련이 없으므로 이메일이 정확히 한 번 발송 되는 것은 아님
- 카프카 토픽에서 읽어서 데이터베이스에 저장하는 경우
- 카프카가 아닌 외부 데이터베이스에 결과물을 쓰는 경우(프로듀서가 사용되지 않고, 레코드는 DB에 쓰고 오프셋은 컨슈머에 의해 카프카에 커밋되는 경우)에는 파티션에 대한 오프셋 커밋과 데이터베이스의 트랜잭션 커밋을 원자적으로 수행할 방법이 없음(하나의 트랜잭션으로 관리 불가능)
이러한 문제에 대한 일반적인 해법은 “아웃박스 패턴”을 사용
아웃박스 패턴 “아웃박스”란 보낼 편지함이라는 뜻으로, 발행할 이벤트를 저장하는 공간, 임시 메시지 큐의 역할을 하며, 엔터티의 업데이트와 하나의 트랜잭션으로 묶임.
마이크로 서비스에서는 “아웃박스”라고 불리는 카프카 토픽에 메시지를 쓰는 작업까지만 하고, 별도의 메시지 중계 서비스가 카프카로부터 메시지를 읽어와서 DB에 업데이트를 진행한다.(아웃박스 패턴 더보기)
[주문 도메인 예시]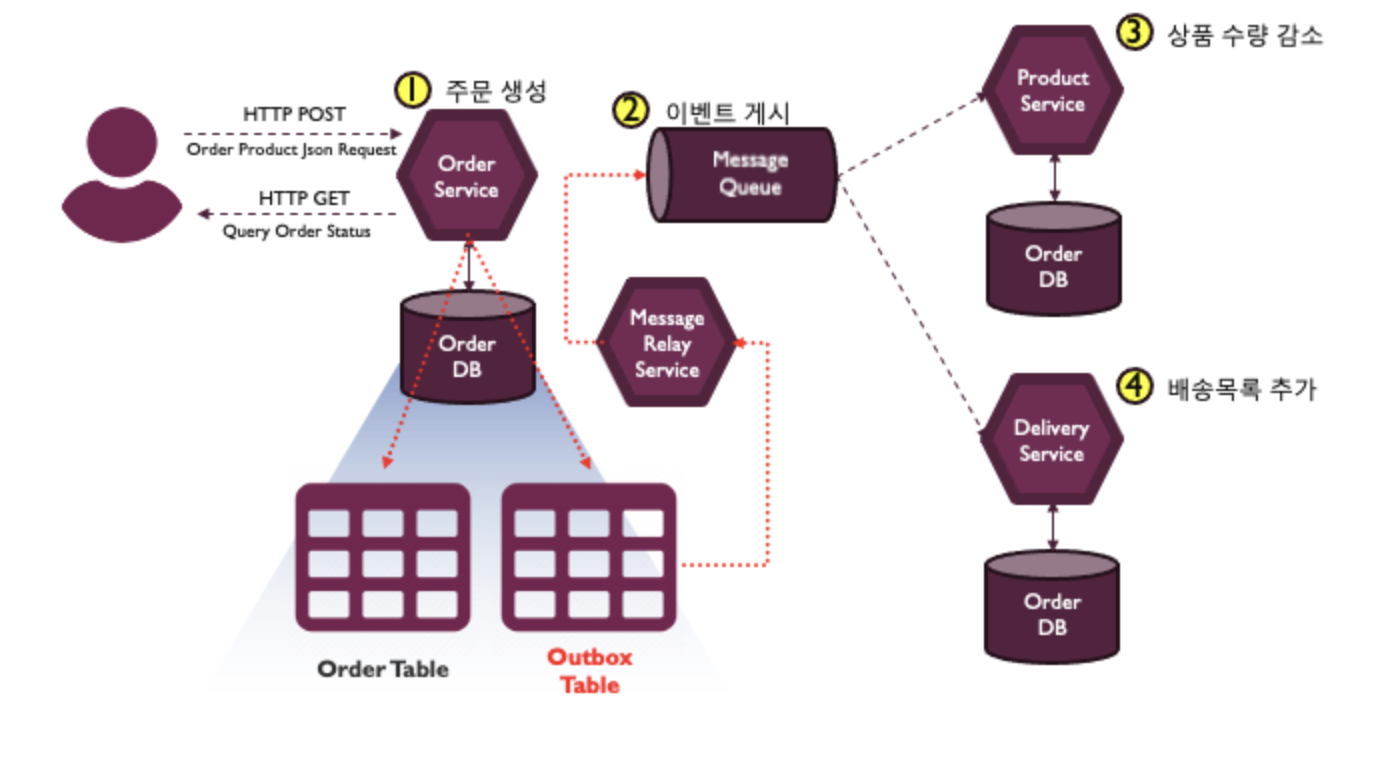 주문 데이터베이스의 주문 테이블에 새로운 주문 정보를 추가할때 Outbox 테이블에는 발행해야할 이벤트를 저장하고, Commit을 수행
주문 데이터베이스의 주문 테이블에 새로운 주문 정보를 추가할때 Outbox 테이블에는 발행해야할 이벤트를 저장하고, Commit을 수행
그럼 별도 프로세스, 그림의 메시지 릴레이 서비스가 Outbox 테이블에 저장된 이벤트를 읽어서 메시지 브로커에 전송한 다음 메시지가 전송되었다는 걸 Outbox 테이블에 표시한 후 삭제
데이터가 유실되거나 메시지 전송에 실패하는 문제를 해결 가능
- 데이터베이스에서 읽어서, 카프카에 쓰고, 데이터베이스에 저장하는 경우
- 카프카는 end-to-end 보장이 안됨.
- 카프카 컨슈머의 read_commited 보장은 DB 트랜잭션을 보존하기엔 너무 약함
- 트랜잭션 경계를 알 수 있는 방법이 없음
- 한 클러스터에서 다른 클러스터로 데이터 복제
- 카프카 클러스터에서 다른 카프카 클러스터로 데이터를 복사할때는 “정확히 한 번”을 보장
- 애플리케이션이 여러개의 레코드와 오프셋을 메시지를 트랜잭션적으로 쓰더라도, 미러메이커를 통한 클러스터간 데이터 복제에서 트랜잭션 속성이나 보장은 유실됨
- 발행/구독 패턴
- 발행/구독 패턴은 토픽에서 데이터를 읽고 사용하는 것이 끝이므로 트랜잭션을 통해 커밋된 메시지만 읽어오도록 할 수는 있지만, 해당 데이터에 대한 처리가 중복되는 것은 막을 수 없음
트랜잭션 사용법
가장 일반적이고 권장되는 방법은 카프카 스트림즈에서 processing.guarantee 설정값으로 exactly_once 또는 exactly_once_beta를 주면 "정확히 한 번" 보장 기능 활성화
카프카 스트림즈를 통한 자동 트랜잭션이 아니라 직접 트랜잭션 API를 사용하고 싶다면, KafkaProducer 에서 제공하는 beginTransaction, commitTransaction을 사용
트랜잭션을 적용하기 위해 1) transactional.id 를 프로듀서에 설정, 2) initTransactions 메서드를 호출, 3) 트랜잭션 내에서 sendOffesetsToTransaction 메서드로 오프셋을 커밋해야만 원자적으로 메시지들과 오프셋들이 여러 파티션들에 쓰이면서 “트랙잭션을 보장함”
트랜잭션 ID와 펜싱
“정확히 한 번” 보장하려면 트랜잭션 ID가 동일한 에플리케이션 인스턴스가 재시작 했을 때는 일관되어야 하지만, 서로 다른 애플리케이션 인스턴스에 대해서는 서로 달라야함
트랜잭션 ID를 정적으로 대응시켜 보는 펜싱 방법(카프카 2.5까지)
각 파티션이 항상 단 하나의 트랜잭션ID에 의해 읽혀짐을 보장
트랜잭션 ID와 컨슈머 그룹 메타데이터를 함께 사용하는 펜싱 방법(카프카 2.5에선)
프로듀서의 오프셋 커밋 메소드르 호출할 시, 컨슈머 그룹ID가 아닌 컨슈머 그룹 메타데이터를 인수로 전달
트랜잭션의 작동 원리
기본적으로 카프카의 트랜잭션은 찬디-램포트 스냅샷(Chandy-Lamport) 알고리즘의 영향을 받아 만들어졌으며, 프로듀서가 트랜잭션을 커밋하기 위해 트랜잭션 코디네이터에 “커밋” 메시지를 보내면 트랜잭션 코디네이터가 트랜잭션 에 관련된 모든 파티션에 커밋 마커를 씀
마커(marker)란?
트랜잭션 마커(transaction marker)를 의미하며, 트랜잭션의 상태를 기록하고 다른 컨슈머에게 해당 트랜잭션이 완료되었거나 중단되었음을 알리는 신호 역할을 수행
트랜잭션이 언제 완전히 처리되었는지 또는 실패했는지를 명확하게 구분짓는 데 사용
Kafka의 트랜잭션 시스템에서는 트랜잭션이 commit되거나 abort되었을 때, 이 상태를 나타내는 트랜잭션 마커가 로그에 기록됨
- Commit Marker: 트랜잭션이 성공적으로 완료되었음을 알리는 마커
이 마커가 기록되면 해당 트랜잭션에 포함된 메시지들이 모두 유효하다는 것을 보장하며, 컨슈머가 이를 읽을 수 있음.- Abort Marker: 트랜잭션이 실패했거나 중단되었음을 알리는 마커
이 마커가 기록되면 해당 트랜잭션에 포함된 메시지들이 무효하다는 것이 컨슈머에게 전달되며, 컨슈머는 이러한 메시지들을 무시해야함
Marker는 Kafka의 트랜잭션 무결성을 유지하기 위해 필수적이며, 됩니다.
⇒ 이런 마커를 보내는중 또는 일부 파티션에만 커밋 메시지가 쓰여진 상태에서 프로듀서가 크래시 나는 경우를 해결하기 위해 2단계 커밋(two-phase commit)과 트랜잭션 로그를 사용.
2단계 커밋(two-phase commit)과 트랜잭션 로그
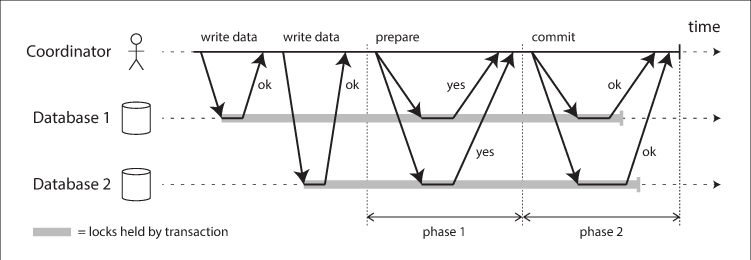
트랜잭션 로그를 사용하며, __transaction_state 라는 이름의 내부 토픽을 사용
아래와 같이 트랜잭션 로그와 two-phase commit 알고리즘을 수행
- 현재 진행중인 트랜잭션이 존재함을 로그에 쓴다. 연관된 파티션들도 모두 기록
- 커밋 혹은 중단 시도를 기록
- 모든 파티션에 트랜잭션 마커를 씀
- 트랜잭션이 종료되었음을 로그에 씀
트랜잭션 코디네이터가 트랜잭션 로그를 관리한다. 트랜잭션 코디네이터는 프로듀서의 트랜잭션 ID 별로 해당하는 트랜잭션 로그의 리더 파티션을 맡은 브로커가 수행한다.
- 실제 프로듀서와 트랜잭션 코디네이터의 동작은 다음과 같이 4단계로 수행
- 프로듀서는
initTransaction()를 호출하여 트랜잭션 코디네이터에게 자신이 새로운 트랜잭션 프로듀서임을 등록. initTransaction()는 코디네이터에 새 트랜잭션 ID를 등록하거나, 기존 트랜잭션ID의 에포크 값을 증가시킴(에포크 값을 증가 시키는 이유는 좀비가 되었을 수 있는 기존 프로듀서들을 펜싱하기 위함) 에포크 값이 증가되면 아직 완료되지 않은 트랜잭션들은 중단됨 beginTransaction()를 호출하면 프로듀서는 다음에 쓰는 메시지부터는 트랜잭션에 포함한 메시지임을 메시지에 명시 (beginTransaction() 호출만으로는 트랜잭션 코디네이터는 트랜잭션이 시작했음을 알 수 없음 ⇒ 그냥 프로듀서에 현재 진행중인 트랜잭션이 있음을 알려줄뿐!)- beginTransaction 메서드를 호출 이후 프로듀서가 메시지를 전송하면 브로커에 추가적으로 AddPartitionsToTxn 요청을 전송하여 메시지가 트랜잭션 내에서 전송되고 있으며, 진행중인 트랜잭션이 있음을 알리고, 이 작업은 로그에 기록됨(1) ⇒
쓰기 작업완료 3번의 쓰기 작업이 완료가 되고 커밋할 준비가 되면 이 트랜잭션에서 처리한 레코드들의 오프셋 부터 커밋함
sendOffsetsToTransaction()를 트랜잭션 코디네이터로 오프셋과 컨슈머 그룹 ID가 포함된 요청이 전송됨 트랜잭션 코디네이터는 컨슈머 그룹ID를 사용해서 컨슈머 그룹 코디네이터를 찾은 뒤, 컨슈머 그룹이 보통하는 것과 같은 방식으로 오프셋을 커밋보통하는 것과 같은 방식으로 오프셋을 커밋한다는 말은?
컨슈머 그룹은 메시지를 읽은 후, 해당 메시지를 처리한 위치(오프셋)를 커밋.
이 커밋된 오프셋 정보는 Kafka의 컨슈머 그룹 코디네이터에 의해 관리되는데, 오프셋 정보는 특별한 토픽 (__consumer_offsets)에 저장됨
즉, 오프셋을 Kafka의__consumer_offsets토픽에 저장하여 이후 메시지 처리에 사용할 수 있도록 하는 일반적인 오프셋 커밋 과정을 의미함commitTransaction(),abortTransaction()을 통해 트랜잭션을 끝내면, 트랜잭션 코디네이터에 EndTxn 요청이 전송되어 커밋, 중단 시도를 로그에 기록(2)- 로그 기록이 끝나면, 모든 파티션에 커밋 또는 중단 마커를 씀(3)
- 마커를 모두 쓰고 난 뒤에 트랜잭션이 종료되었음을 로그에 씀(4)
- 프로듀서는
이 과정을 진행하는 중에 트랜잭션 코디네이터에서 크래시가 발생하더라도 로그를 통해 최종적으로 트랜잭션이 보장됨
3. 트랜잭션 성능
프로듀서 입장
- 트랜잭션 ID 등록 요청, 트랜잭션 종료 시 트랜잭션 커밋 요청은 동기적으로 일어나 오버헤드를 발생
- 메시지의 수와 트랜잭션 오버헤드는 상관관계가 없으므로, 한 트랜잭션 내에 많은 메시지를 보내야 처리량을 증가시킬 수 있음
컨슈머 입장
- 커밋 마커를 읽어오는 작업에서 약간의 오버헤드가 발생
- read_committed 상태의 컨슈머는 트랜잭션 커밋 간격이 길어질수록 컨슈머는 메시지가 리턴될 때까지 더 오랫동안 대기 ⇒ 종단 지연도 그만큼 증가
정리
“정확히 한 번” 의미 구조는 이해하기 어렵지만, 쓰기는 쉽다.
[출처]
https://dongwooklee96.github.io/post/2021/03/26/two-phase-commit-%EC%9D%B4%EB%9E%80/
https://developer.confluent.io/courses/architecture/transactions/