coroutine 알아보기 (1) - 개요
coroutine 개요
코루틴 (Coroutine)
코루틴은 비동기 프로그래밍을 간결하고 효율적으로 작성할 수 있도록 도와주는 Kotlin의 주요 기능입니다. 멀티스레드 프로그래밍보다 더 가볍고 직관적인 방식으로 비동기 작업을 처리할 수 있습니다.
코루틴의 의미
코루틴(Coroutine)이라는 단어는 co-routine으로 구성되며, 여기서 접두사 co는 "협력하는"이라는 의미를 가지고 있습니다.
뒤에 오는 routine은 컴퓨터 공학에서 사용하는 루틴, 즉 함수라고 볼 수 있습니다.
따라서 co-routine은 협력하는 함수라는 의미로, 서로 협력하며 실행 흐름을 나누는 프로그램 구조를 의미합니다.
그냥 routine(함수)도 서로 호출과 반환을 주고받으며 협력합니다.
루틴
그렇다면 그냥 루틴과 코루틴은 어떤 차이가 있을까요? 아래의 코드를 보면서 설명하겠습니다.
kotlin, springboot3.x기준으로 설명합니다.
전체 sample은 github-sample를 참조해주세요.
1
2
3
4
5
6
7
8
9
10
fun main() {
println("START")
newRoutine()
println("END")
}
fun newRoutine() {
val num1 = 1
val num2 = 2
println("${num1 + num2}")
}
main 루틴과 new 루틴이 있습니다. 이 코드를 실행하면 쉽게 아래의 결과가 프린트 됩니다.
1
2
3
START
3
END
위의 과정을 서술하자면 아래와 같습니다.
- main 루틴이 START 를 출력한 이후 new 루틴을 호출한다.
- new 루틴은 1과 2를 계산해 3 을 출력한다.
- 그 이후, new 루틴은 종료되고 main 루틴으로 돌아온다.
- main 루틴은 END 를 출력하고 종료된다.
새로운 루틴이 호출되면, newRoutine()이 사용하는 stack에 지역변수 num1 과 num2가 초기화되고, 루틴이 끝나면 해당 메모리(num1 과 num2)에 접근이 불가능합니다.
이 말을 조금 더 루틴이라는 단어를 사용해서 풀어보자면…
- 루틴은 진입하는 곳이 한 곳이다.
- 루틴이 종료되면 그 루틴에서 사용했던 정보가 초기화된다.
로 정리할 수 있습니다.
코루틴
위에서 루틴의 코드를 보았으니 아래는 코루틴의 코드를 설명해봅니다.
build.gradle.kts에 아래를 추가합니다.
1
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.8.1")
코루틴의 협력 방식을 설명하기 위해 아래와 같이 코드를 작성하였습니다. 어떤 의미인지 설명해보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
fun main(): Unit = runBlocking { // runBlocking에 의해 coroutine이 하나 생성됨.
printWithThread("Start")
launch { // 반환값이 없는 코루틴을 만든다. 새로 생기는 코루틴을 바로 실행하지않는다.
newRoutine()
}
yield()
printWithThread("End")
}
// suspend : 다른 suspend fun을 호출할 수 있다.
// yield()가 suspend fun 이기 때문에 필요
suspend fun newRoutine() {
val num1 = 1
val num2 = 2
yield() // 지금 코루틴을 중단하고 다른 코루틴이 실행되도록 스레드를 양보한다
printWithThread(num1 + num2)
}
fun printWithThread(str: Any) {
println("[${Thread.currentThread().name}] $str")
}
- runBlocking : 일반 루틴 세계와 코루틴 세계를 연결하는 함수. 이 함수 자체로 새로운 코루틴을 만들게 되고, runBlocking 에 넣어준 람다가 새로운 코루틴 안에 들어가게 됩니다.
- launch : 새로운 코루틴을 만드는 함수. 주로 반환 값이 없는 코루틴을 만드는데 사용됨.
- yield : 지금 코루틴의 실행을 잠시 멈추고 다른 코루틴이 실행되도록 양보.
- suspend fun : 다른 suspend fun을 호출하는 능력부여
위의 설명에서 봤듯이 위의 코드는 runBlocking { } 과 launch { } 를 사용해 2개의 코루틴을 만든 것입니다. 위으 코드 실행결과는 아래와 같습니다.
1
2
3
START
END
3
위의 과정을 서술하자면 아래와 같습니다.
- main 코루틴이 runBlocking 에 의해 시작되고 START 가 출력된다.
- launch 에 의해 새로운 코루틴이 생긴다. 하지만, newRoutine의 실행은 바로 일어나지않는다.
- main 코루틴 안에 있는 yield() 가 되면 main 코루틴은 new 코루틴에게 실행을 양보한다. 따라서 launch 가 만든 새로운 코루틴이 실행되고, newRoutine 함수가 실행된다.
- newRoutine 함수는 다시 yield() 를 호출하고 main 코루틴으로 되돌아온다.
- main 루틴은 END 를 출력하고 종료된다.
- 아직 newRoutine 함수가 끝나지 않았으니 newRoutine 함수로 되돌아가 3 이 출력되고 프로그램이 종료된다.
그림으로 그려보자면 아래와 같습니다.
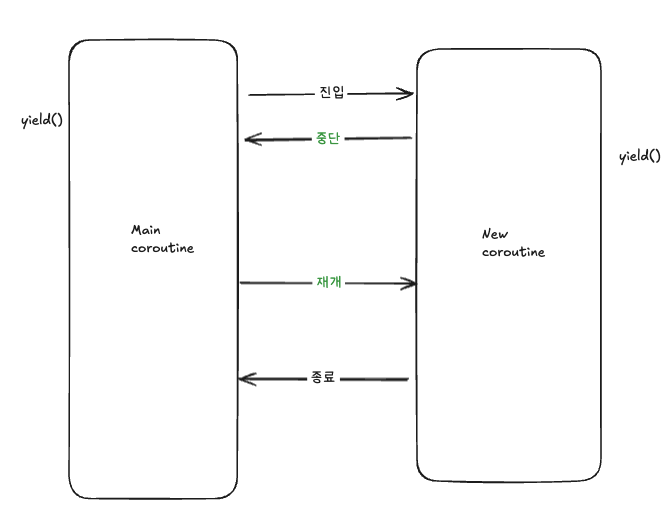
정리하자면 루틴과 코루틴의 가장 큰 차이는 중단과 재개입니다.. 루틴은 한 번 시작되면 종료될 때 까지 멈추지 않지만, 코루틴은 상황에 따라 잠시 중단이 되었다가 다시 시작되기도 하는것입니다.
그렇기 때문에 완전히 종료되기 전까지는 newRoutine 함수 안에 있는 num1 num2 변수가 메모리에서 제거되지도 않다는 점을 기억해야합니다.
코루틴이 어떤 스레드에서 수행되었는지 확인하려면 -Dkotlinx.coroutines.debug를 vm option으로 추가해주면 된다. test시에는 아래와 같이 추가해주면 된다.
정리
- 루틴
- 시작되면 끝날 때까지 멈추지 않는다.
- 한 번 끝나면 루틴 내의 정보가 사라진다.
- 코루틴
- 중단되었다가 재개될 수 있다.
- 중단되더라도 루틴 내의 정보가 사라지지 않는다.
스레드와 코루틴
우선 개념부터 짚고 넘어갈 필요가 있습니다.
- 프로세스 : 컴퓨터에서 실행되고 있는 프로그램을 의미
- 스레드 : 프로세스보다 작은 개념으로 프로세스에 소속되어 여러 코드를 동시에 실행할 수 있도록 해줌.
스레드는 코드를 실행하고 따라서 우리가 작성한 코드는 특정 스레드에서 실행됩니다.
만약 한 프로세스가 여러 개의 스레드를 갖고 있다면 멀티스레드 환경이라고 합니다.
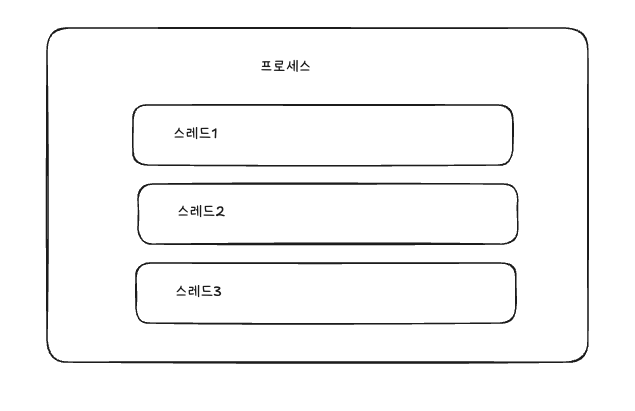
코루틴은 스레드보다 작은 개념입니다.
가장 먼저 코루틴은 단지 우리가 작성한 루틴, 코드의 종류 중 하나이기 때문에 코루틴 코드가 실행되려면 스레드가 있어야만 합니다.
그런데 코루틴은 중단되었다가 재개될 수 있기 때문에, 코루틴 코드의 앞부분은 1번 스레드에 배정되고, 뒷부분은 2번 스레드에 배정될 수 있습니다. 아래 그림을 보면서 설명하겠습니다.
아래를 보면먼저 아직 작업이 할당되지 않은 스레드1,2가 있고, 코루틴은 3개가 존재합니다. 코루틴 1에는 코드1, 중단지점, 코드2가 있는 코루틴입니다. 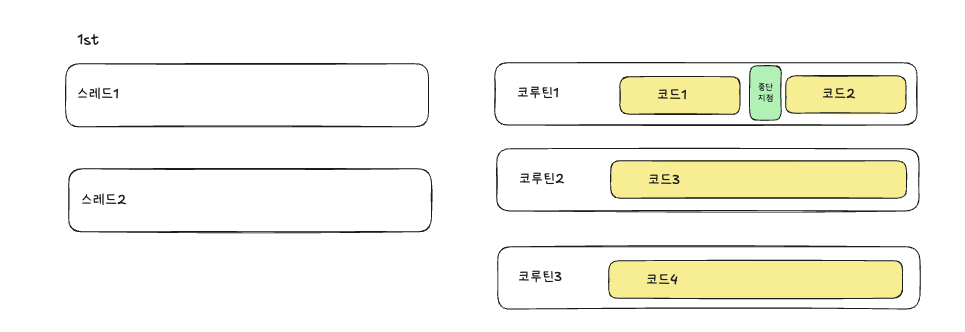
코드1이 스레드1에, 코드3이 스레드2에 할당되었습니다. 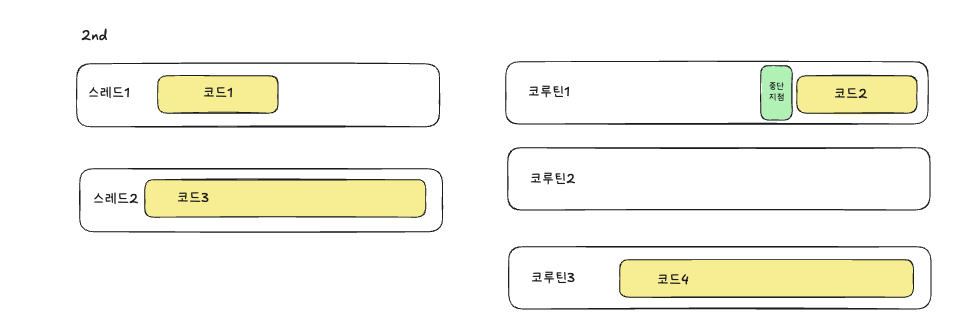
스레드2는 아직 코드3을 처리중이고, 스레드1이 코루틴1의 코드1을 수행을 다 끝내고 중단지점을 만나서 중단됩니다. 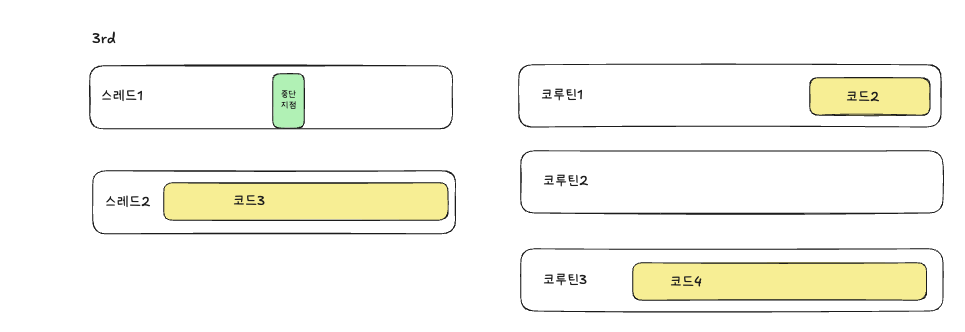
스레드2는 아직 코드3을 처리중이여서, 코루틴3의 코드4를 스레드1이 가져와 처리합니다. 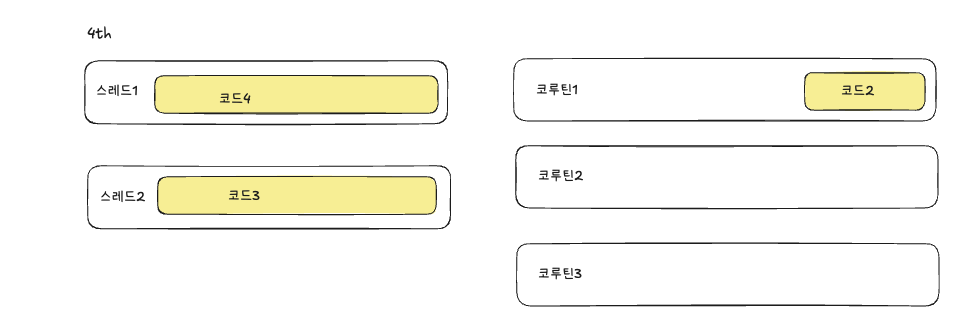
스레드2가 코드3을 처리한 후 나머지 아까 중단되었던 코루틴1의 나머지 코드2를 가져와 작업을 수행합니다. 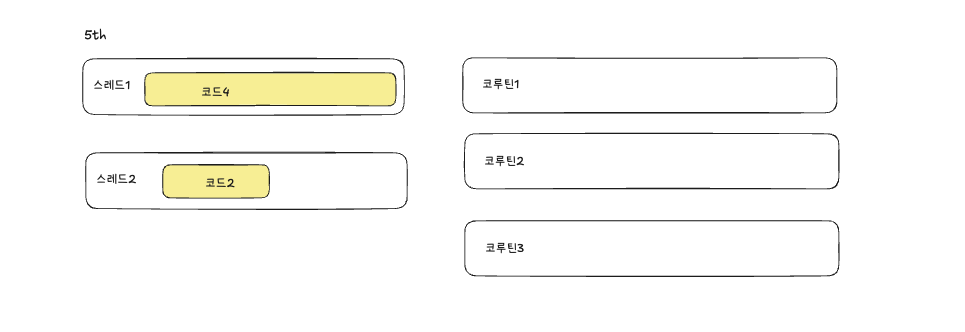
코루틴1의 코드1은 스레드1에서 실행되었지만, 코루틴1의코드2는스레드2에서실행되었습니다.
위에서 본 것처럼 코루틴이 중단되었다가 재개될 때 다른 스레드에 배정될 수 있습니다.
또한 스레드와 코루틴의 차이점은 context switching 과정에서도 차이가 있습니다.
스레드에서 context switching이 일어날 경우 Heap 메모리를 공유하고, Stack만 교체되므로 Process보다는 비용이 작습니다.
그러나, 동일 스레드에서 코루틴이 실행된다면 메모리 전부를 공유하므로 스레드보다 context swithcing 비용이 낮습니다.
아래의 그림을 보면서 설명해보겠습니다. 코루틴1은 코드1, 중단지점, 코드2를 포함하고 있고, 코루틴2는 코드3을 포함하고 있습니다. 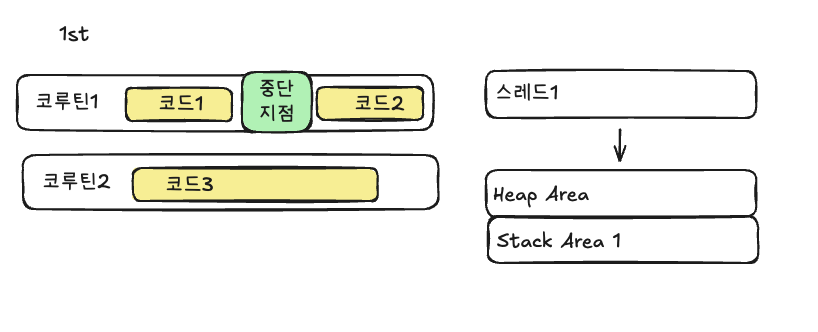
스레드1에 코루틴1이 할당되고, 코드1과 중단지점이 실행되었습니다. 스레드에 할당될 때 heap area, stack area에 코드를 써내려갈 것 입니다. 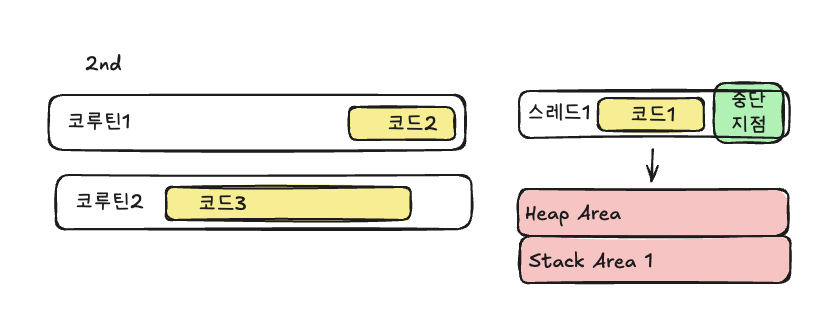
중단지점을 만났기에 코루틴1 스스로가 다른 코루틴에게 자리를 양보하면서 코루틴2의 코드3이 스레드1에 할당됩니다.
이때, 스레드가 바뀌지않았기 때문에 기존 코루틴1이 사용했던 heap area, stack area를 공유할 수 있게되는 것입니다.
즉, heap area, stack area를 공유할 수 있게되는 것은 메모리를 공유하는 것이므로 스레드보다 context switching 비용이 낮다는 말입니다. 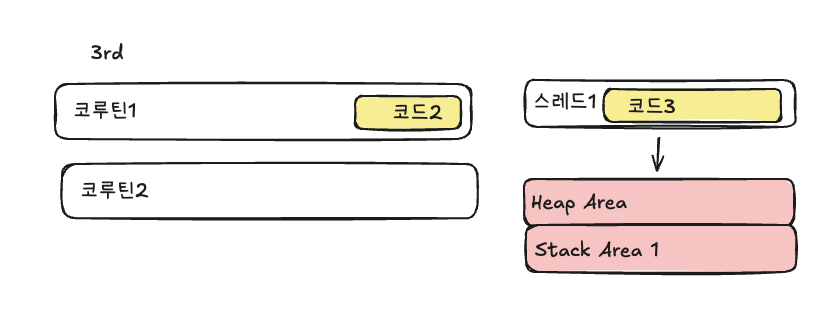
이때 마치 두 코루틴이 동시에 실행된는 것 처럼 보이는데 하나의 스레드에서는 한가지일만 할 수 있지만 아주 빠르게 작업이 전환되어 동시에 하는 것 처럼 보이는 것입니다.
- 프로세스
- 프로세스는 각각 독립된 메모 리 영역을 갖고 있기 때문에 1번 프로세스에서 2번 프로세스로 실행이 변경되면 힙 영역과 스탭 영역이 모두교체되어야 한다.
- 프로세스 간의 context switching은 비용이 제일 크다.
- 스레드
- 스레드는 독립된 스택 영역을 가지고 있지만, 힙 영역을 공유하고 있기 때문에 실행이 변경되면 스택 영역만 교체된다.
- 프로세스보다는 context switching 비용이 적다.
- 코루틴
- 코루틴은 1번 코루틴과 2번 코루틴이 같은 스레드에서 실행될 수 있다.
- 동일한 스렏드에서 코루틴이 실행되면, 메모리 전부를 공유하므로 스레드보다 context switching 비용이 적다.
그리고 스레드는 동시성을 확보하기 위해 여러 개의 스레드가 필요합니다. 반면, 코루틴은 1번 코루틴과 2번 코루틴이 하나의 스레드에서 번갈아 실행될 수 있기 때문에 단 하나의 스레드만으로도 동시성을 확보할 수 있습니다.
코루틴은 yield()를 사용했던 것 처럼 스스로가 다른 코루틴에게 실행을 양보할 수 있습니다. 반면에 스레드는 보통 OS가 실행되고 있는 스레드를 멈추고 다른 스레드가 실행되도록합니다.
이처럼 코루틴과 같은 방식을 “비선점형”이라고 부르고, 스레드와 같은 방식을 “선점형”이라고 부릅니다.
정리
- 스레드
- 프로세스보다 작은 개념
- 한 스레드는 오직 한 프로세스에만 포함되어 있다.
- context switching 발생 시 stack 영역이 교체된다.
- os가 스레드를 강제로 멈추고 다른 스레드를 실행한다.
- 코루틴
- 스래드 보다 작은 개념
- 한 코루틴 코드는 여러 스레드에서 샐행될 수 있다.
- 한 스레드에서 실행하는 경우 context switching 발생 시 메모리 교체가 없다.
- 코루틴 스스로가 다른 코루틴에게 양보한다.
[출처]
- https://kotlinlang.org/docs/coroutines-overview.html