Recursive CTE VS. Application Aggregation
댓글 트리 조회 성능 비교 및 최종 선택
재귀 CTE vs 애플리케이션 집계
웹 애플리케이션에서 마주치는 ‘계층형 데이터 조회’, 특히 ‘게시글별 상위 N개 댓글 트리 조회’ 기능을 구현하며 고민했던 두 가지 접근 방식, 재귀 CTE(Common Table Expressions)와 애플리케이션 레벨 집계를 비교 분석한 경험을 공유하고자 합니다.
요구사항
현재 mysql 8 이상, springboot를 사용중이며, “특정 게시글(post_id)에 달린 댓글 중, 총점(루트 댓글 + 모든 자손 댓글의 점수 합)이 가장 높은 상위 3개의 댓글 트리를 조회”하는 것입니다.
테이블 스키마는 아래와 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
CREATE TABLE post_comment (
id INT PRIMARY KEY,
parent_id INT NULL,
review VARCHAR(100) NOT NULL,
created_on DATETIME NOT NULL,
score INT NOT NULL,
post_id INT NOT NULL,
CONSTRAINT fk_parent
FOREIGN KEY (parent_id) REFERENCES post_comment(id)
ON DELETE CASCADE
);
-- 탐색 성능을 위해 인덱스 생성
CREATE INDEX ix_post_parent ON post_comment (post_id, parent_id);
이 문제를 해결하기 위해 Recursive CTE 방식과 Application Aggregation 방식에 대해 설명하고 실험하여 채택한 방법에 대해 설명합니다.
mysql8, kotlin, springboot3.x기준으로 설명합니다. 전체 sample은 github-sample를 참조해주세요.
1. Recursive CTE
첫 번째 방식은 MySQL 8.0 이상에서 지원하는 재귀 CTE와 윈도우 함수를 활용해 모든 계산과 필터링을 데이터베이스 내에서 끝내는 것입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
WITH RECURSIVE
post_comment_score (id, root_id, post_id, parent_id, review, created_on, score) AS (
-- 1. 루트 댓글 (parent_id IS NULL)
SELECT id, id AS root_id, post_id, parent_id, review, created_on, score
FROM post_comment
WHERE post_id = ?1 AND parent_id IS NULL -- ?1: 파라미터 바인딩
UNION ALL
-- 2. 자식 댓글을 재귀적으로 탐색
SELECT pc.id, pcs.root_id, pc.post_id, pc.parent_id, pc.review, pc.created_on, pc.score
FROM post_comment pc
JOIN post_comment_score pcs
ON pc.parent_id = pcs.id
),
total_score_comment AS (
-- 3. 루트별 총점 합산 (윈도우 함수)
SELECT
id, parent_id, review, created_on, score, root_id,
SUM(score) OVER (PARTITION BY root_id) AS total_score
FROM post_comment_score
),
total_score_ranking AS (
-- 4. 총점 기준 랭킹 계산 (윈도우 함수)
SELECT
id, parent_id, review, created_on, score, total_score,
DENSE_RANK() OVER (ORDER BY total_score DESC) AS ranking
FROM total_score_comment
)
-- 5. 상위 3개 트리만 추출
SELECT id, parent_id, review, created_on, score, total_score
FROM total_score_ranking
WHERE ranking <= 3
ORDER BY total_score DESC, id ASC;
- 장점:
- 네트워크 효율성: DB가 모든 계산(재귀, 집계, 랭킹)을 수행한 뒤 정확히 필요한 데이터(상위 3개 트리)만 애플리케이션에 전송합니다. 데이터 양이 많을수록 압도적으로 유리합니다.
- 데이터 일관성: 단일 쿼리(스냅샷) 내에서 모든 계산이 이루어지므로 데이터 일관성이 보장됩니다.
- “DB가 잘하는 일”: 집계, 필터링, 정렬은 관계형 데이터베이스의 핵심 기능입니다.
- 단점:
- 쿼리가 복잡하고 길어져 유지보수가 어려울 수 있습니다.
- DB(MySQL)의 CPU 자원을 상대적으로 많이 사용합니다.
2. Application Aggregation
DB에서는 특정 post_id에 해당하는 모든 댓글을 일단 조회한 뒤(Flat list), 애플리케이션(Kotlin/Spring) 메모리상에서 트리 구조를 조립하고 총점을 계산하여 필터링하는 방식입니다.
- pseudo code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
fun findTopCommentTreesWithAggregation(postId: Long, limit: Int): List<CommentNode> {
// 1. DB에서 post_id에 해당하는 모든 댓글 조회
val rows: List<CommentRow> = postCommentRepository.findAllRowsByPostId(postId)
// 2. ID를 키로 하는 맵 생성 (트리 조립을 위해)
val nodes = rows.associate {
it.id to CommentNode(
id = it.id,
parentId = it.parentId,
review = it.review,
createdOn = it.createdOn,
score = it.score
)
}
// 3. 루트 노드 리스트
val roots = mutableListOf<CommentNode>()
// 4. O(n) 순회로 트리 조립
nodes.values.forEach { node ->
if (node.parentId == null) {
roots.add(node) // 루트 노드 추가
} else {
// 자식 노드를 부모의 children 리스트에 추가
nodes[node.parentId]?.children?.add(node)
}
}
// 5. 총점 계산(lazy) 후 정렬 및 상위 N개 필터링
return roots
.sortedByDescending { it.totalScore } // 이 시점에 totalScore가 계산됨
.take(limit)
}
- 장점:
- DB 부하가 적습니다. (단순 SELECT … WHERE post_id = ?)
- 애플리케이션에서 비즈니스 로직을 제어하기 유연하며, 쿼리가 단순해집니다.
- 조회한 전체 데이터를 캐싱하거나 다양한 형태로 가공하기 용이합니다.
- 단점:
- 네트워크 비효율성: 댓글이 10,000개라면 10,000개 데이터를 모두 네트워크를 통해 전송받은 뒤, 애플리케이션에서 단 3개를 고르기 위해 버리게 됩니다.
- 애플리케이션 메모리/CPU 사용: 데이터가 많을수록 애플리케이션 서버의 메모리와 CPU 사용량이 증가하며, GC 부담이 생길 수 있습니다.
부하테스트로 성능 비교해보기
저는 이 두 방식 중 어떤 방식을 사용할지 모킹한 데이터로 검증하기 위해 성능 테스트 환경을 구축했습니다.
자세한 사항은 테스트 환경 관련 문서 참조)
- 장비 : Mac M4, memroy : 24GB, SSD : 512GB
- 애플리케이션: Spring Boot 3, Kotlin, JPA
- 테스트 데이터: 10,000개의 댓글 더미 데이터를 생성하는 SQL 스크립트 활용
- 부하 테스트: k6를 사용해 CTE 엔드포인트와 Aggregation 엔드포인트에 동일한 시나리오(예: 2분간 VU 100까지 증가)로 부하 발생
- 모니터링: Actuator, Micrometer, Prometheus, Grafana를 연동하여 k6의 응답 시간(p95, p99)과 애플리케이션의 내부 지표(JVM, DB Connection Pool, GC)를 동시에 관찰
이번 실험에서는 DB Connection Pool은 관찰하지 않았습니다.
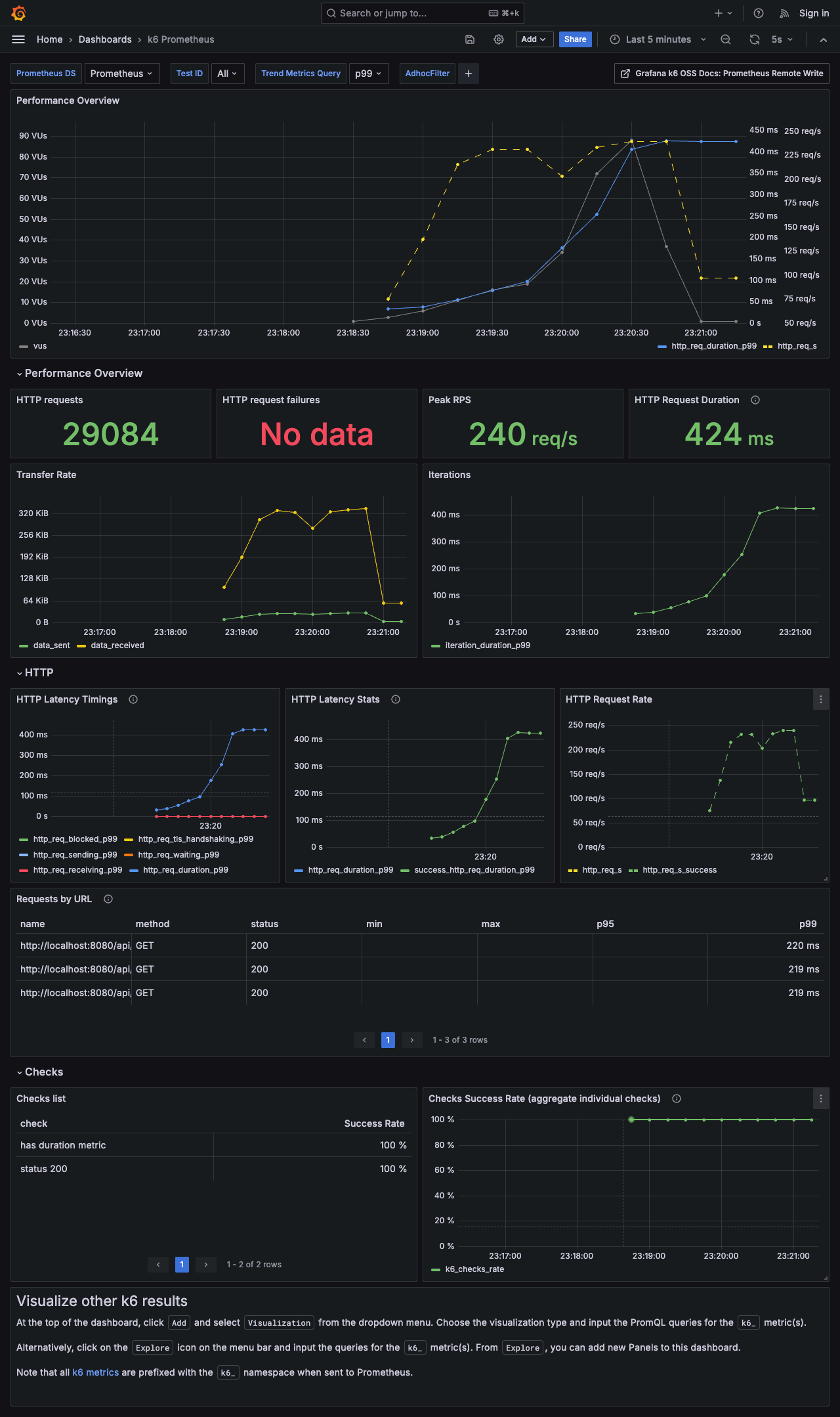
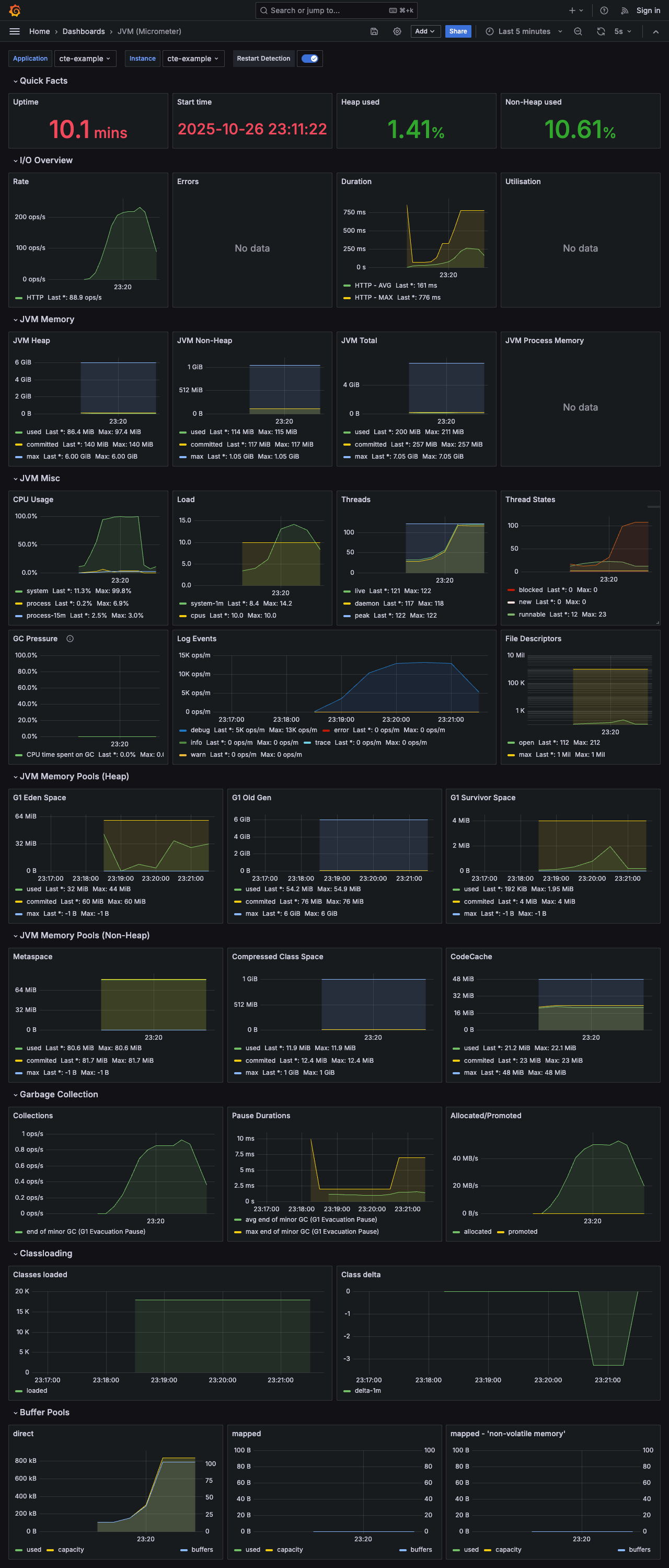
1. CTE 방식 모니터링 결과
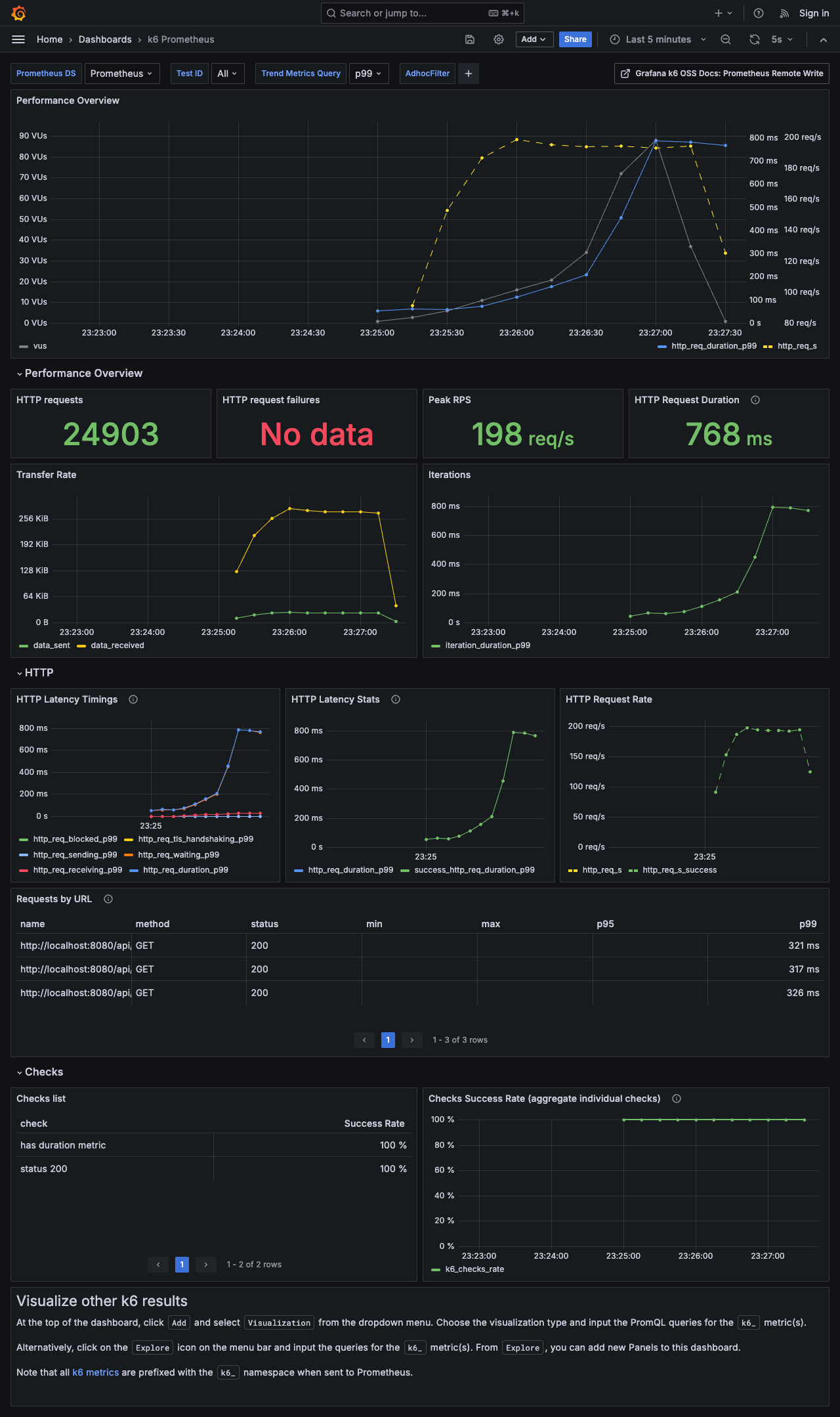
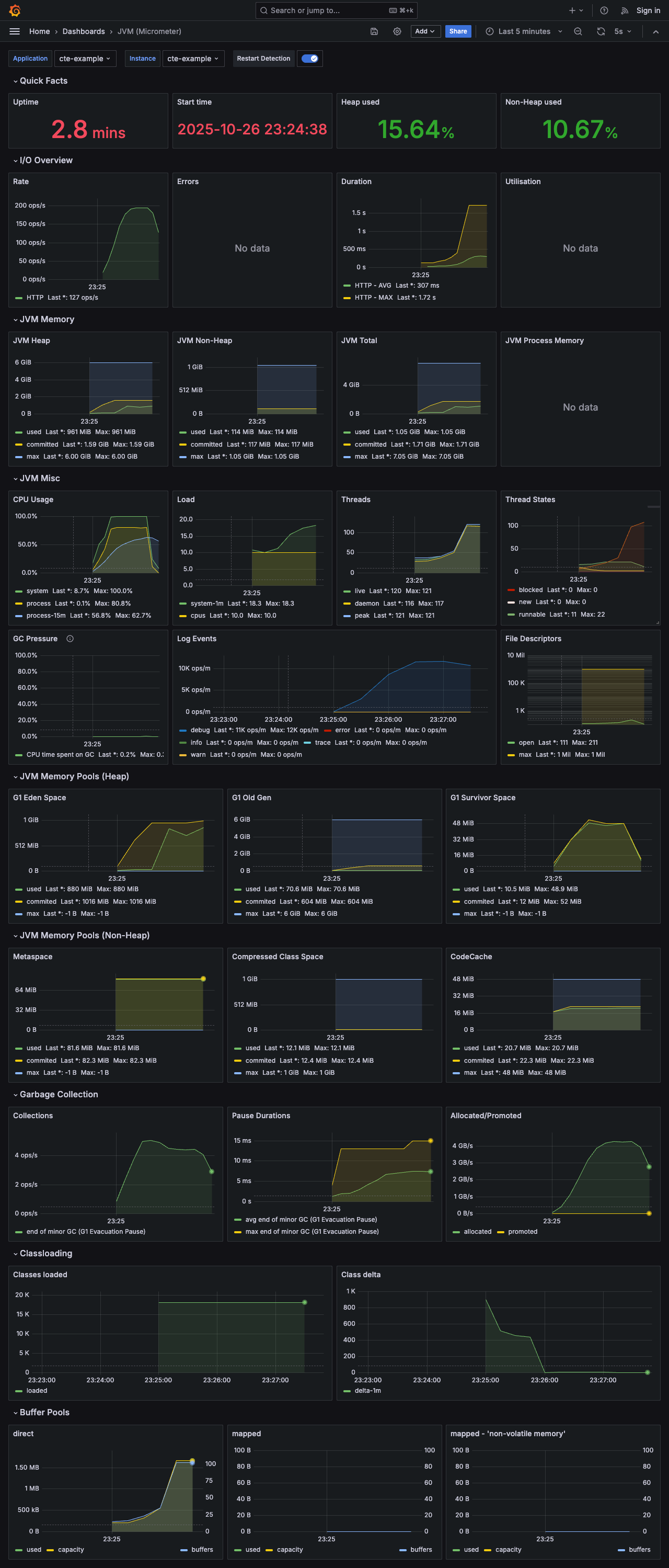
2. Aggregation 방식 모니터링 결과
결과 분석
위에 k6 부하 테스트 결과를 보면 아래의 지표에서 차이가 보입니다.
- 처리량 (Throughput)
- CTE 방식은 2분 30초의 테스트 시간 동안 약 5,000건 더 많은 요청을 성공적으로 처리했습니다.
- Peak RPS(초당 최대 요청 수) 또한 CTE 방식이 50RPS 가량 더 높게 측정되었습니다.
- 응답 시간 (Latency)
- p99(상위 99%) 기준 Latency가 CTE는 424ms인 반면, Aggregation 방식은 768ms로 거의 두 배에 가까운 지연 시간을 보였습니다.
- 시스템 리소스 (JVM)
- Aggregation 방식은 10,000건의 데이터를 모두 애플리케이션 메모리로 가져와 처리해야 하므로, JVM 힙 메모리 사용량이 높게 측정되었습니다.
- 반면, CTE 방식은 DB가 계산을 전담하고 애플리케이션은 필터링된 최소한의 데이터만 받기 때문에, JVM이 매우 안정적인 상태를 유지했습니다.
방식 선택
데이터셋 크기(10,000개)와 부하 정도에 따라 결과는 달라질 수 있지만, 저의 요구사항(“상위 3개 트리 조회”)에 기반하여 저는 ‘재귀 CTE’ 방식을 최종 선택했습니다.
CTE 방식 vs Java Aggregation 방식 비교 정리
- 문제 정의: Top-K 트리 조회
- 요구사항은 “전체 트리 조회”가 아닌 “Top-K 트리만 필터링” 입니다.
- 즉, 모든 댓글 트리를 가져온 뒤 상위 N개만 추리는 Aggregation 방식보다,DB 단계에서 필요한 데이터만 추출하는 CTE 방식이 훨씬 효율적입니다.
- CTE(Common Table Expression)를 이용하면, 재귀 쿼리로 필요한 트리만 미리 필터링한 뒤 결과를 반환할 수 있습니다.
- 네트워크 비용 관점
- 댓글이 약 1만 건 존재한다고 가정할 때 Aggregation 방식(Java) -> 1만 건 전체를 직렬화하여 네트워크로 전송하고, 애플리케이션 메모리에 모두 로드한 후 필터링 수행합니다.
- CTE 방식(DB) -> Top-K 트리(수십~수백 건) 만 추출 후 전송하며 CTE 방식은 데이터 전송량 및 직렬화 비용을 획기적으로 절감합니다.
- 실제 k6 부하 테스트에서 응답 시간(p95) 지표 차이로 그 효과가 확인되었습니다.
- 애플리케이션 서버 부하 관점
- Aggregation 방식은 대용량 데이터 로딩 시 힙 메모리 사용량 급증 -> OOM(Out Of Memory) 위험 -> GC 부하 증가 -> 응답 지연 및 스루풋 감소
- 반면, CTE 방식은 계산 부하를 DB로 위임하여 애플리케이션 서버의 리소스 사용을 안정적으로 유지할 수 있습니다.
단, DB에 연산 부하가 집중되므로 쿼리 튜닝 및 인덱스 최적화는 필수입니다. 그리고 재귀적 CTE를 잘못 사용한다면 매우 성능이 떨어집니다.
결론
DB 부하를 반드시 줄여야하는 쪽 보다는 “요구사항에 맞게 적절하게 처리해야한다.”입니다.
저의 ‘Top-K’ 요구사항에는 CTE가 가장 적합하였습니다.